2021. 1. 11. 12:22ㆍ교육과정/KOSMO
키워드 : 파이썬 함수 개념 추가 / 파이썬 지역 변수 / 파이썬 글로벌 변수 / 파이썬 맵리듀스 / 리눅스 조건 연산자 / 리눅스 파일 관련 옵션 / 리눅스 논리 연산자 / 리눅스 반복문 for, while / 리눅스 쉘 함수 호출 / 아파치 플럼 다운로드 및 설치
****
0. 파이썬 복습
(1) unpacking
| list = [1, 2, 3] a, b, c = list |
(2) compregension
: 요소 생성시 for 문과 if문 결합
| list = [i for i in range(10, 100, 10) if i <=50 ] list = [10, 20, 30, 40, 50] |
(3) 함수의 인자
| *args : 여러 개의 인자를 하나의 튜플로 받아서 처리 **kwargs : 여러 개의 인자를 하나의 딕셔너리로 받아서 처리 |
※ 복습 연습문제
(1) 다음과 같이 코드를 작성했을 때, 실행 결과로 알맞은 것은?
|
mylist = ['apple' ,'banana', 'grape'] |
➀ [('apple', 1), ('banana', 2), ('grape', 3)]
➁ [(1, 'apple'), (2, 'banana'), (3, 'grape')]
➂ [(0, 'apple'), (1, 'banana'), (2, 'grape')]
➃ [('apple', 0), ('banana', 1), ('grape', 2)]
➄ [('grape',0), ('banana',1), ('apple',2)]
답 : ③
(풀이)
enumerate()는 순서를 붙여 튜플로 만드는 함수
[(0, apple), (1, banana), (2, grape)]
(2) 다음과 같이 코드를 작성했을 때, 실행 결과로 알맞은 것은?
|
cat_song = "my cat has blue eyes, my cat is cute" |
➀ {0: 'my', 1: 'cat', 2: 'has', 3: 'blue', 4: 'eyes,', 5: 'my', 6: 'cat', 7: 'is', 8: 'cute'}
➁ {'my': 0, 'cat': 1, 'has': 2, 'blue': 3, 'eyes,': 4, 'my': 5, 'cat': 6, 'is': 7, 'cute': 8}
➂ {0: 'my', 1: 'cat', 2: 'has', 3: 'blue', 4: 'eyes,', 5: 'is', 6: 'cute'}
➃ {'my': 5, 'cat': 6, 'has': 2, 'blue': 3, 'eyes,': 4, 'is': 7, 'cute': 8}
➄ 오류
답 : ③
(풀이)
enumerate(cat_song.slit()) == (0, my) (1, cat) (2, has) (3, blue) (4, eyes,) (5, my) (6,cat) (7, is) (8, cute)
{i:j} == { my:0, cat:1, has:2, blue:3, eyes,:4,
my:5, cat:1, has:2, blue:3, eyes,:4,
my:5, cat:6, has:2, blue:3, eyes,:4, is:7, cute:8 }
딕셔너리에서 중복이 제거되면서 같은 key값의 value는 나중 것으로 덮어씌여진다.
(3) 다음과 같이 코드를 작성했을 때, 예측되는 실행 결과를 쓰시오.
|
colors = ['orange', 'pink', 'brown', 'black', 'white'] |
답 :
orange&pink&brown&black&white(풀이)
join( ) 함수는 특정 문자열로 리스트를 구분지어준다.
(4) 다음 코드의 실행 결과를 쓰시오.
|
user_dict = {} |
답 :
{'students': 0, 'superuser': 1, 'professor': 2, 'employee': 3}(풀이)
user_list = ["students","superuser", "professor", "employee"] 일 때,
enumerate(user_list) == (0, students), (1, superuser), (2, professor), (3, employee)
user_dict[value_2] = value_1 에서 value_2가 key가 되고 value_1이 value가 되므로,
{'students': 0, 'superuser': 1, 'professor': 2, 'employee': 3}
(5) 다음 코드의 실행 결과를 쓰시오.
|
animal = ['Fox', 'Dog', 'Cat', 'Monkey', 'Horse', 'Panda', 'Owl'] |
답 :
['Cat', 'Panda', 'Owl'](풀이)
[ani for ani in animal if 'o' not in ani] 를 풀어 쓰면
if 'o' not in ani:
ani for ani in animal: 이므로,
ani는 'o'를 포함하지 않는 요소로 이루어진 리스트가 된다.
(6) 다음 코드의 실행 결과를 쓰시오.
|
name = "Hanbit University" |
답 :
DongUniversity(풀이)
split_name = ["Hanbit", "University"]
join_student = 'HongGilDong'
join_student[-4:] == 'Dong'
split_name[1] == 'University'
print(join_student[-4:] + split_name[1]) == DongUniversity
(7) 다음과 같은 결과값을 출력하기에 적당한 함수를 빈칸에 쓰시오.
|
>>> alist = ['a1', 'a2', 'a3'] |
답 :
zip
(8) 다음과 같이 코드를 작성했을 때, 예측되는 실행 결과를 쓰시오.
|
>>> a = [1, 2, 3] |
① [[6, 3], [9, 2], [24, 3]]
② [[12, 3], [15, 3]]
③ [[12, 3], [15, 3], [17, 3]]
④ 오류
⑤ [[12, 3], [15, 3], [12, 2]]
답 : ②
(풀이)
zip(a, b, c)의 결과는 [ (1, 4, 7), (2, 5, 8) ] 이고,
for k in zip(a, b, c)의 결과는 (1, 4, 7)과 (2, 5, 8) 이다.
sum(k)의 결과는 1+4+7=12 와 2+5+8=15 이고,
len(k)의 결과는 3과 3 이므로
print([[sum(k), len(k)] for k in zip(a, b, c)]) 의 실행결과는
[ [12, 3], [15, 3] ] 가 된다.
(9) 다음 코드의 실행 결과를 쓰시오.
|
week = ['mon', 'tue', 'wed', 'thu', 'fri', 'sat', 'sun'] |
답 :
yellow(풀이)
list_data[1] 는 rainbow 이고
list_data[1][2] 는 rainbow[2] 를 가리키므로 yellow가 출력된다.
(10) 다음 코드의 실행 결과를 쓰시오.
|
kor_score = [30, 79, 20, 100, 80] |
답 :
score:72(풀이)
midterm_score[2] 는 eng_score 이고
midterm_score[2][1] 는 eng_score[1] 에 해당한다.
따라서, print(midterm_score[2][1]) 를 실행하면 72 가 출력된다.
(11) 다음 코드의 실행 결과를 쓰시오.
|
alist = ["a", "b", "c"] |
답 :
['a', '2', 'error'](풀이)
zip(alist, blist) 는 ('a', '1') ('b', '2') ('c', '3') 이고,
enumerate() 를 적용하면
(a, b)의 튜플 구조를 갖는 (0, ('a', '1')) (1, ('b', '2')) (2, ('c', '3')) 가 된다.
a : 0, 1, 2
b : ('a', '1'), ('b', '2'), ('c', '3')
따라서, b[a] 는 ('a', '1')[0] == 'a'
('b', '2')[1] == '2'
('c', '3')[2] == 없음 .. 'error'
실행결과 abcd = ['a', '2', 'error'] 가 출력된다.
(12) 다음 코드의 실행 결과를 쓰시오.
|
alphabet = ["a", "b", "c", "d", "e", "f", "g", "h"] |
답 : 80
alphabet = ["a", "b", "c", "d", "e", "f", "g", "h"] 총 8개
nums == [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19] 총 20개
alpha for alpha in alphabet == ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']
for alpha in alphabet for num in nums if num%2==0 를 풀어 쓰면
if num % 2 == 0
for num in nums:
for alpha in alphabet: 이므로
num 이 짝수일 때 반복문에서 num * alpha 횟수만큼 두 종류의 문자가 결합한다.
len(answer) 은 answer 에 있는 요소의 갯수를 구하는 것이므로 8 * 10 = 80 이 출력된다.
print(answer) = ['a0', 'a2', 'a4', 'a6', 'a8', 'a10', 'a12', 'a14', 'a16' ... 'h14', 'h16', 'h18']
1. 파이썬 함수 개념 추가
(1) 함수도 메모리에 올라가는 객체가 될 수 있다.
def case1():
print('case-1')
def case2():
print('case-2')
def case3():
print('case-3')
f = {'case1':case1, 'case2':case2, 'case3':case3}
a = 'case3'
f[a] # f['case3'] == case-3
f[a]()
# 실행결과
'''
case-3
'''
(2) 자바에서의 지역변수와 파이썬에서의 지역변수
| # JAVA : 블록 안에서 선언한 변수가 지역 변수 # 파이썬 : 함수 안에서 선언한 변수가 지역 변수 |
if True:
test = '변수'
print(test)
# 실행결과
'''
변수... if 문은 함수가 아니다! 제어문이다.
'''
(3) 파이썬에서의 글로벌 변수와 지역 변수
| # 함수 안에서 선언한 변수는 지역변수가 된다. |
temp = '글로벌'
def func():
# print('0>', temp) ... 지역변수가 있을 경우에는 지역변수 선언보다 앞에서 변수를 사용할 수 없다.
temp = '지역'
print('1>', temp)
func()
print('2>', temp)
# 실행결과
'''
1>지역
2>글로벌
'''
| # 지역변수는 함수 밖에서 글로벌변수로 사용할 수 없다. |
def func():
temp = '지역'
print('1>', temp)
func()
# print('2>', temp) ... 에러 발생
# 실행결과
'''
1> 지역
'''
| # 함수 안에서 global 이라고 선언해줄 경우, 지역변수가 아닌 글로벌 변수가 되어 함수 밖에서도 사용할 수 있다. |
def func():
global temp
temp = '지역'
print('1>', temp)
func()
print('2>', temp)
# 실행결과
'''
1> 지역
2> 지역
'''
(4) 람다 함수
| # 람다함수 - 한번 사용하고 버리는 함수 # 파이썬에서는 람다함수를 한 줄로 작성하기도 한다. # 람다함수 사용시 직관적이지 않다는 이유로 파이썬 3.x부터는 람다를 권장하지 않는 경우가 많으나 종종 사용된다. |
# original 함수 --- 2줄
def f(x,y):
return x*y
print(f(2,3))
# 실행결과
'''
6
'''
# lambda 함수 (축약형) --- 1줄
f = lambda x,y: x*y
print(f(2,3))
# 실행결과
'''
6
'''
(5) 맵리듀스
| (1) map() ` 연속 데이터를 저장하는 시퀀스 자료형에서 요소마다 같은 기능을 적용할 때 사용 ` 형식 : map(함수명, 리스트형식의 입력값) ` 파이썬 3.x에서는 list(map(calc, ex)) 반드시 list를 붙여야 리스트 형식으로 반환된다 파이썬 2.x에서는 list 없이도 리스트 형식으로 반환 (2) reduce() ` 리스트 같은 시퀀스 자료형에 차례대로 함수를 적용하여 모든 값을 통합하는 함수 파이썬 2.x에서는 많이 사용하던 함수이지만, 최근 문법의 복잡성으로 권장하지 않는 추세이다. |
(1) 맵 map( )
※ map(a, b) 사용시 b 에서 요소를 하나씩 뽑아서 a 에 넣어서 연산을 수행하고,
결과를 출력하기 위해서는 리스트( list )를 사용한다.
※ 함수의 인자로 리스트의 요소를 하나씩 넣고 결과 역시 리스트로 받을 수 있다.
def calc(x):
return x**2
ex = [1,2,3,4,5]
map (calc, ex)
print(list(map(calc, ex)))
# 실행결과
'''
[1, 4, 9, 16, 25]
'''
(2) 리듀스 reduce( )
※ reduce 클래스를 import 해야 한다.
※ reduce(a, b) 사용시 b 에서 요소를 하나씩 뽑아서 a 에 넣어서 연산을 수행하고,
그 결과값들로 다시금 연산하여 최종 하나의 값을 얻는다.
→ 차례대로 뽑는다. → 함수를 수행한다. → 모든 값을 통합한다.
from functools import reduce
def f(x,y):
return x*y
print(reduce(f, range(1,6)))
# 실행결과
'''
120
'''(풀이)
range(1,6) == [1,2,3,4,5]
def f(x, y) = x * y
reduce(f, range(1,6)) == [1,2,3,4,5]
1 * 2 = 2 ┘
2 * 3 = 6 ┘
6 * 3 = 24 ┘
24 * 5 = 120
※ 연습문제
(1) 다음 코드를 람다 함수 형태로 수정할 때, 알맞은 코드를 작성하시오.
|
def f(x, y): |
답 :
f = lambda x,y: x**y(풀이)
람다 함수로 작성시에는, 인자를 먼저 적고 : 이후에 리턴값을 작성한다.
(2) 다음과 같이 리스트 컴프리헨션으로 되어 있는 코드를 람다(lambda) 함수와 map() 함수를 사용하여 표현하시오.
|
>>> ex = [1, 2, 3, 4, 5] |
답 :
f = lambda x : x**2
print(list(map(f, ex)))
print(list(map(lambda x : x**2, [1,2,3,4,5]) ) )
# 실행결과
'''
[1, 4, 9, 16, 25]
'''(풀이)
[value **2 for value in ex] 는
리스트 ex 의 요소를 하나씩 뽑아낸 뒤, 제곱을 한 결과가 들어있는 리스트이다.
함수를 람다식으로 나타내면 f = lambda x : x**2 이고,
map(f, ex) 의 결과를 리스트로 출력하려면 print(list(map(f, ex)))가 된다.
(3) 다음과 같이 코드를 작성했을 때, 예측되는 실행 결과를 쓰시오.
|
>>> def transpose_list(two_dimensional_list): |
답 :
[ (1,2,3) (4,5,6) (7,8,9) ]
(풀이)
실행될 함수는
def transpose_list(two_dimensional_list):return [row for row in zip(*two_dimensional_list)] 이다.
return [row for row in zip(*two_dimensional_list)] 는
two_dimensional_list 전체를 받아서 zip( ) 함수로 새로운 튜플 구조를 만든다.
[[1, 4, 7], [2, 5, 8], [3, 6, 9]] 에 zip( ) 함수가 적용된 튜플 구조는
(1,2,3) (4,5,6) (7,8,9) 이고,
리스트로 전체를 감싸면 [ (1,2,3) (4,5,6) (7,8,9) ] 가 출력된다.
(4) 다음 코드의 실행 결과를 쓰시오.
|
>>> date_info = {'year': "2019", 'month': "9", 'day': "6"} |
답 :
2019-9-6(풀이)
date_info는 딕셔너리 구조이며 key와 value에 따른 출력은
{'year': "2019", 'month': "9", 'day': "6"} 이다.
key값인 year, month, day 에 해당하는 value를 출력하면
2019-9-6 이 출력된다.
(5) n개의 벡터의 크기가 동일한지 확인하는 함수를 한 줄의 코드로 작성하시오.
|
a=(1,2,3)
a=(1,2,3) |
답 :
vector_size_check = lambda a,b,c: len(a)==len(b)==len(c) (풀이)
len(a)==len(b)==len(c) 의 결과는 True 또는 False로 나오게 된다.
(6) 다음과 같이 2개 이상의 행렬을 더하는 코드를 작성하시오. [ 답제공 ]
|
>>>matrix_y = [[2, 5], [2, 1]] |
답 :
(풀이)
matrix_addition = lambda a,b : a[0]*b[0]
>>>matrix_y = [[2, 5], [2, 1]]
>>>matrix_z = [[2, 4], [5, 3]]
>>>matrix_addition(matrix_y, matrix_z)
[[4, 9], [7, 4]]2. 리눅스 - 조건 연산자
※ 리눅스에서 한 줄씩 입력하는 대신 여러 줄을 한 번에 입력하기 위해 쉘 프로그래밍을 활용할 수 있다.
※ 컴파일 언어가 아니기 때문에 문법 오류를 찾아내기 어렵다.
| * 조건연산자 |
| -eq | 값이 같다 (equal) |
| -ne | 값이 다르다 (not equal) |
| -gt | 값1이 값2보다 크다 (greater than) |
| -ge | 값1이 값2보다 크거나 같다 (greater or equal) |
| -lt | 값1이 값2보다 작다 (less than) |
| -le | 값1이 값2보다 작거나 같다 (less or equal) |
| -! | 조건이 성립하지 않음 |
(1) root 계정 로그인 후 shelltest 디렉토리로 이동한다.
[root@localhost shelltest]# cd shelltest
[root@localhost shelltest]# pwd
/root/shelltest
(2) vi 에디터로 condi3.sh 파일을 생성하고 작성 후 저장한다.
[root@localhost shelltest]# vi condi3.sh
i#!/bin/sh
if [ 100 -eq 200 ]
then
echo "같다"
else
echo "다르다"
fi
exit 0
:wq
(3) sh 명령어로 condi3.sh 파일을 실행하여 결과를 확인한다.
[root@localhost shelltest]# sh condi3.sh
3. 리눅스 - 파일 관련 옵션
| * 파일 관련 옵션 |
| -f | : 파일이면 True |
| -d | : 디렉토리이면 True |
| -e | : 존재하면 True |
| -r | : 읽기 가능하면 True |
| -w | : 쓰기 가능하면 True |
| -x | : 실행 가능하면 True |
| -s |
: 파일의 크기가 0이 아니라면 true |
(1) 파일 관련 옵션을 테스트 하기 위한 condi4.sh 파일을 vi 에디터로 생성한다.
| 테스트 할 옵션 : -f .......... fn이 파일인가? |
[root@localhost shelltest]# vi condi4.sh
i#!/bin/sh
fn=/root/anaconda-ks.cfg
if [ -f $fn ]
then
head -5 $fn
else
echo 'not a file'
fi
exit 0:wq
(2) 파일이면 5줄을 출력하고, 아닐 경우 echo의 내용을 출력하는지 확인하기 위해 sh 명령어로 condi4.sh를 실행한다.
| 실행결과 : 파일 O, 조건문에 의해 상위 5라인이 출력된다. |
[root@localhost shelltest]# sh condi4.sh
#version=DEVEL
# System authorization information
auth --enableshadow --passalgo=sha512
# Use CDROM installation media
cdrom
(3) 실행시 파일명을 함께 입력하면 조건문에서 결과에 따라 출력되도록 쉘 스크립트를 수정한다.
| 테스트 할 옵션 : -f ..........명령행 매개변수( $1 )로 읽어오는 이름 fn이 파일인가? |
#!/bin/sh
fn=$1
if [ -f $fn ]
then
head -5 $fn
else
echo 'not a file'
fi
exit 0
(4) 매개변수에 따른 출력결과가 알맞은지 확인한다.
|
실행결과 ① : 파일 O, 조건문에 의해 상위 5라인이 출력된다. |
# ①
[root@localhost shelltest]# sh condi4.sh /root/anaconda-ks.cfg
#version=DEVEL
# System authorization information
auth --enableshadow --passalgo=sha512
# Use CDROM installation media
cdrom
# ②
[root@localhost shelltest]# sh condi4.sh /root
not a file
4. 리눅스 - 논리 연산자
| * 논리연산자 : && , | | |
| if [ A ] && [ B ] if [ A ] -a [ B ] if [ A ] | | [ B ] if [ A ] -o [ B ] ※ 주의 if [ A && B ] 는 안 된다. |
(1) 논리연산자 옵션을 테스트 하기 위해 condi4.sh 파일을 vi 에디터로 수정한다.
두 가지 조건을 모두 충족하는지 확인하기 위해 && 연산자를 사용한다.
|
테스트 할 옵션 : -f ..........명령행 매개변수( $1 )로 읽어오는 이름 fn이 파일인가? |
#!/bin/sh
fn=$1
if [ -f $fn ] && [ -s $fn ]
then
head -5 $fn
else
echo 'not a file'
fi
exit
(2) 매개변수가 포함된 sh 명령어를 입력하여 논리연산자의 수행 결과를 확인한다.
| 실행결과 ① : 파일 O && 용량이 0보다 큼, 조건문에 의해 상위 5라인이 출력된다. |
[root@localhost shelltest]# sh condi4.sh ./var1.sh
#!/bin/sh
myvar='Hello'
echo $myvar
(3) 두 가지 조건을 모두 충족하는지 확인하기 위해 -a 연산자를 사용한다.
| 테스트 할 옵션 : -f ..........명령행 매개변수( $1 )로 읽어오는 이름 fn이 파일인가? 테스트 할 옵션 : -s ..........명령행 매개변수( $1 )로 읽어오는 이름 fn의 용량은 0보다 큰가? |
#!/bin/sh
fn=$1
if [ -f $fn -a -s $fn ]
then
head -5 $fn
else
echo 'not a file'
fi
exit
(4) 매개변수가 포함된 sh 명령어를 입력하여 논리연산자의 수행 결과를 확인한다.
| 실행결과 ① : 파일 O && 용량이 0보다 큼, 조건문에 의해 상위 5라인이 출력된다. |
[root@localhost shelltest]# sh condi4.sh ./var1.sh
#!/bin/sh
myvar='Hello'
echo $myvar
5. 리눅스 - 반복문
(1) for
| ① for 변수 in 값1 값2 값3 do 반복실행문장 done |
| ② for 변수 in `seq 초기값 마지막값` ※ 역따옴표 주의! do 반복실행문장 done |
| ③ for ( ( 초기값 ; 조건문 ; 증가치 ) ) do 반복실행문장 done |
| ④ for i in { 초기값 .. 마지막값 } do 반복실행문장 done |
(2) while
| ① while [ 조건문 ] do 반복실행문장 done |
(3) break / continue
(4) 함수 / return
6. 리눅스 - 반복문 연습문제 (1)
(1) for 반복문 실습을 위해 condi5.sh 파일을 vi 에디터로 생성한다.
[root@localhost shelltest]# vi condi5.sh
i
(2) 1~5까지의 합을 구하는 쉘 스크립트를 작성한다.
#!/bin/sh
result=0
for i in 1 2 3 4 5
do
result=`expr $result + $i` # 역따옴표 주의!
done
echo 'sum=' $result
:wq
(3) sh 명령어로 실행하여 반복문 안의 연산 결과가 정상적으로 수행되는지 확인한다.
[root@localhost shelltest]# sh condi5.sh
(4) 다른 종류의 for문을 사용하여 같은 결과를 출력해본다.
#!/bin/sh
result=0
① for i in `seq 1 5`
② for ((i=1;i<6;i++))
③ for i in {1..5}
do
result=`expr $result + $i` # 역따옴표 주의!
done
echo 'sum=' $result
※ [ 예제 ] 1부터 100까지 수에서 홀수의 합과 짝수의 합 출력
★ ( `expr` 밖에서 =과 +연산자에 공백을 주지 않도록 한다. )
#!/bin/sh
for i in `seq 1 100`
do
if [ `expr $i % 2` == 0 ]
then
even=`expr $even + $i`
else
odd=`expr $odd + $i`
fi
done
echo "짝수의 합 : "$even
echo "홀수의 합 : "$odd
exit 0
( 실행결과 )
짝수의 합 : 2550
홀수의 합 : 2500
7. 리눅스 - 반복문 연습문제 (2)
(1) 파일명을 for 반복문에서 사용하기 위해 condi7.sh 파일을 vi 에디터로 생성한다.
[root@localhost shelltest]# vi condi7.sh
(2) 쉘 스크립트를 작성한다.
| condi로 시작하는 . sh 파일 목록에서 파일 이름에 해당하는 fname을 출력하는 반복문을 작성한다. |
#!/bin/sh
for fname in $(ls condi*.sh)
do
echo $fname
done
(3) 출력결과를 확인한다.
[root@localhost shelltest]# sh condi7.sh
condi.sh
condi2.sh
condi3.sh
condi4.sh
condi5.sh
condi7.sh
8. 리눅스 - 반복문 연습문제 (3)
(1) 파일명을 매개변수로 받아 반복문에서 사용하기 위해 condi7.sh 파일을 vi 에디터로 연다.
[root@localhost shelltest]# vi condi7.sh
i
(2) 쉘 스크립트를 수정한다.
| condi로 시작하는 . sh 파일 목록에서 각 파일마다 filename 이라는 key 값에 대해 이름에 해당하는 fname을 출력하는 반복문을 작성한다. |
#!/bin/sh
for fname in $(ls condi*.sh)
do
echo 'filename:' $fnamedone
tail -3 $fname
done
:wq
(2) 결과를 출력해본다.
filename:
fi
filename:
stop ) echo "종료합니다" ;;
* ) echo "start 또는 stop을 입력해주세요" ;;
esac
filename:
fi
exit 0
filename:
fi
exit
filename:
echo 'sum=' $result
filename:
echo 'filename:' $fnamedone
tail -3 $fname
done
※ while 문 실습
[ 연습 ] 1부터 10까지의 합 출력
[ 실행 ] sh condi8.sh
[ 프로세스 확인 ] ps -ef | grep condi8.sh
컴퓨터 학대 중이라면
[ 프로세스 종료 ] kill -9 PID값
[root@localhost shelltest]# vi condi8.sh
i#!/bin/sh
sum=0
i=0
while [ $i -le 10 ]
do
sum=`expr $sum + $i`
i=`expr $i + 1`
done
echo "1부터 10까지의 합:" $sum
exit 0:wq
9. 리눅스 쉘 함수 호출
: 사용자로부터 입력된 값 num1과 num2가 add 라는 함수를 호출할 때 인자로 들어가서 나머지 연산이 수행된다.
(명령행 매개변수가 처리되는 방식과 비슷한듯!!)

#!/bin/sh
#함수 선언
add()
{
total=`expr $1 + $2`
echo 'total=' $total
}
#함수 호출
echo 'enter first number:'
read num1
echo 'enter second number:'
read num2
add $num1 $num2(실행결과)
[root@localhost shelltest]# ./condi9.sh
enter first number:
1
enter second number:
2
total= 3
10. 아파치 플럼 설치
※ 아파치 플럼 ( Apache Flume ) ?
: 연속적으로 생성되는 데이터 스트림을 HDFS 에 수집 및 전송하고 저장하는데 사용되며,
통신 프로토콜, 메시지 포맷, 발생주기, 데이터 크기 등과 관련된 여러가지 기능과 아키텍처를 제공한다.
: 데이터 스트림에는 로그파일, 소셜 미디어 데이터, 이메일 메시지 등이 있다.
[ 플럼 참고 ] kerpect.tistory.com/62
[ 카프카 참고 ] kerpect.tistory.com/63?category=874039
※ 아파치 홈페이지에서 파일만 다운 받을 수 있는 경로
(1) 리눅스의 파이어폭스에서 http://apache.mirror.cdnetworks.com/ 접속
(2) 목록에서 flum/ 클릭
(3) 목록에서 1.9.0/ 클릭
(4) 웹페이지 주소와 apache-flume-1.9.0-bin.tar.gz 라는 파일명을 합친다.
http://apache.mirror.cdnetworks.com/flume/1.9.0/apache-flume-1.9.0-bin-tar.gz (주소창에 위의 내용을 입력했을 때 다운로드가 바로 나타나야 정상적이다. )
(5) 리눅스 터미널에서 /home/centos 디렉토리로 이동 후 tmp 디렉토리를 생성한다.
[root@localhost centos]# mkdir tmp
[root@localhost centos]# ls
abc test tmp 공개 다운로드 문서 바탕화면 비디오 사진 서식 음악
(6) 작업경로를 tmp 디렉토리로 변경한다.
[root@localhost centos]# cd tmp
(7) 터미널에서 wget 명령어를 사용하여 설치파일을 다운받는다.
[root@localhost tmp]# wget apache.mirror.cdnetworks.com/flume/1.9.0/apache-flume-1.9.0-bin.tar.gz
--2021-01-14 18:39:19-- http://apache.mirror.cdnetworks.com/flume/1.9.0/apache-flume-1.9.0-bin.tar.gz
Resolving apache.mirror.cdnetworks.com (apache.mirror.cdnetworks.com)... 14.0.101.165
Connecting to apache.mirror.cdnetworks.com (apache.mirror.cdnetworks.com)|14.0.101.165|:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 67938106 (65M) [application/x-gzip]
Saving to: ‘apache-flume-1.9.0-bin.tar.gz’
100%[===================================>] 67,938,106 40.1MB/s in 1.6s
2021-01-14 18:39:21 (40.1 MB/s) - ‘apache-flume-1.9.0-bin.tar.gz’ saved [67938106/67938106]
(8) tmp 디렉토리에 아파치 플럼 설치파일이 다운받아져 있는지 확인한다.
[root@localhost tmp]# ls
apache-flume-1.9.0-bin.tar.gz
(9) gzip 파일의 압축을 풀기 위해 tar 명령어에 zxvf 옵션을 주어 입력하면 설치까지 완료된다.
[root@localhost tmp]# tar zxvf apache-flume-1.9.0-bin.tar.gz
apache-flume-1.9.0-bin/conf/
apache-flume-1.9.0-bin/bin/
...
(10) apache-flume-1.9.0-bin 디렉토리가 존재하므로 아파치 플럼이 설치되었음을 확인할 수 있다.
[root@localhost tmp]# ls
apache-flume-1.9.0-bin apache-flume-1.9.0-bin.tar.gz
(11) 아파치 플럼이 설치된 디렉토리의 구성을 확인할 수 있다.
[root@localhost tmp]# ls apache-flume-1.9.0-bin
CHANGELOG LICENSE README.md bin doap_Flume.rdf lib
DEVNOTES NOTICE RELEASE-NOTES conf docs tools
(12) 루트 디렉토리에서 opt 하위에 새 디렉토리를 생성한다.
1.9.0 디렉토리 생성시 flume 디렉토리도 함께 생성될 수 있도록 -p 옵션을 추가한다.
[root@localhost tmp]# mkdir -p /opt/flume/1.9.0* 리눅스의 opt 디렉토리는 윈도우의 Program Files 폴더와 비슷한 역할로 응용 프로그램이 위치하는 곳이다.
* 운영체제와 응용 프로그램들은 서로 분리시켜야 하는데,
1) 운영체제 파일을 응용 프로그램 파일로 덮어쓰는 것을 방지하고,
2) 응용 프로그램을 모듈화하여 추가, 삭제, 수정을 용이하게 하기 위함이다.
[ 참고 ] 리눅스 시스템의 디렉토리 구조와 기능
https://firedev.tistory.com/entry/Linux-Unix-리눅스시스템-디렉토리-구조와-기능
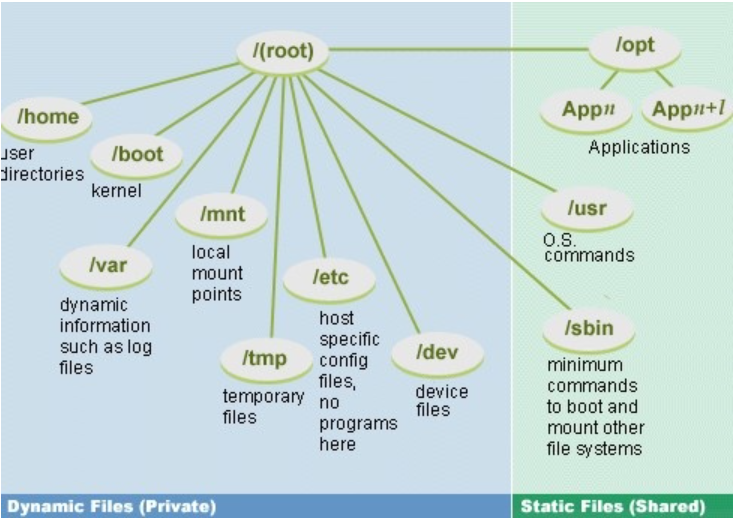
(13) 디렉토리가 모두 만들어졌는지 확인한다.
[root@localhost tmp]# ls /opt
flume rh
[root@localhost tmp]# ls /opt/flume
1.9.0
[root@localhost tmp]# ls /opt/flume/1.9.0
[root@localhost tmp]#
(14) 아파치 플럼의 모든 디렉토리와 파일을 새로 만든 1.9.0 디렉토리로 옮긴다.
[root@localhost tmp]# mv apache-flume-1.9.0-bin/* /opt/flume/1.9.0/
(15) 빈 디렉토리가 된 apache-flume-1.9.0-bin 디렉토리와 압축파일을 삭제한다.
[root@localhost tmp]# ls apache-flume-1.9.0-bin
[root@localhost tmp]# ls
apache-flume-1.9.0-bin apache-flume-1.9.0-bin.tar.gz
[root@localhost tmp]# rm -rf apache-*
[root@localhost tmp]# ls
[root@localhost tmp]#
(16) install_flume.sh 파일을 만들 수 1.8.0 버전을 설치할 수도 있다.
# sh install_flume.sh 1.8.0