2021. 2. 2. 22:18ㆍ교육과정/KOSMO
키워드 : 판다스 파일 읽기 / 판다스 문자열 연습 / 판다스 화살표 주석 / 판다스 subplot / 판다스 시각화 선과 색, 범례 / 판다스 제공 / 판다스 한글처리 / 시각화가 필요한 이유 / 판다스 평가 /
****
1. 판다스 파일 읽기 (1)
csv 파일로 저장하기
import pandas as pd
mysource = {
'시도':['서울','경기','인천','부산','대전'],
'구분':['특별시','도','광역시','광역시','광역시'],
'인구':['999만','1300만','400만','600만','300만'],
'면적':[600.9, 10171, 1234.5, 747.8, 459.1]
}
mysource
{'시도': ['서울', '경기', '인천', '부산', '대전'],
'구분': ['특별시', '도', '광역시', '광역시', '광역시'],
'인구': ['999만', '1300만', '400만', '600만', '300만'],
'면적': [600.9, 10171, 1234.5, 747.8, 459.1]}(1) 우선 DataFrame으로 만든다.
→ dict타입보다 DataFrame으로 변경할 경우 보다 손쉽게 파일로 저장할 수 있다.
df = pd.DataFrame(mysource)
df
| 시도 | 구분 | 인구 | 면적 | |
|---|---|---|---|---|
| 0 | 서울 | 특별시 | 999만 | 600.9 |
| 1 | 경기 | 도 | 1300만 | 10171.0 |
| 2 | 인천 | 광역시 | 400만 | 1234.5 |
| 3 | 부산 | 광역시 | 600만 | 747.8 |
| 4 | 대전 | 광역시 | 300만 | 459.1 |
(2-1) csv로 만들 수 있다. → 컬럼명과 데이터타입도 그대로 따라온다.
df.to_csv('./result/temp.csv')
(2-2) excel 로 만들 수 있다.
df.to_excel('./result/temp.xlsx')
csv 파일을 읽어오는 방법
temp.csv 파일에서 읽어서 df1 변수가 가리키도록 하고 출력
(1) csv 파일을 읽어온다. 이 때, index명이 데이터로 같이 들어와버리므로 별도 처리가 필요하다.
pd.read_csv('파일경로')
df1 = pd.read_csv('./result/temp.csv')
df1
| Unnamed: 0 | 시도 | 구분 | 인구 | 면적 | |
|---|---|---|---|---|---|
| 0 | 0 | 서울 | 특별시 | 999만 | 600.9 |
| 1 | 1 | 경기 | 도 | 1300만 | 10171.0 |
| 2 | 2 | 인천 | 광역시 | 400만 | 1234.5 |
| 3 | 3 | 부산 | 광역시 | 600만 | 747.8 |
| 4 | 4 | 대전 | 광역시 | 300만 | 459.1 |
(2) 하나의 컬럼을 index 컬럼으로 지정한다.
index_col='컬럼명'
df1 = pd.read_csv('./result/temp.csv', index_col='Unnamed: 0')
df1
| 시도 | 구분 | 인구 | 면적 | |
|---|---|---|---|---|
| 0 | 서울 | 특별시 | 999만 | 600.9 |
| 1 | 경기 | 도 | 1300만 | 10171.0 |
| 2 | 인천 | 광역시 | 400만 | 1234.5 |
| 3 | 부산 | 광역시 | 600만 | 747.8 |
| 4 | 대전 | 광역시 | 300만 | 459.1 |
컬럼명 지정
df1 = pd.read_csv('./result/temp.csv', names=['No', '시도', '구분', '인구', '면적'])
df1
| No | 시도 | 구분 | 인구 | 면적 | |
|---|---|---|---|---|---|
| 0 | NaN | 시도 | 구분 | 인구 | 면적 |
| 1 | 0.0 | 서울 | 특별시 | 999만 | 600.9 |
| 2 | 1.0 | 경기 | 도 | 1300만 | 10171.0 |
| 3 | 2.0 | 인천 | 광역시 | 400만 | 1234.5 |
| 4 | 3.0 | 부산 | 광역시 | 600만 | 747.8 |
| 5 | 4.0 | 대전 | 광역시 | 300만 | 459.1 |
→ 파일의 첫 줄이 컬럼명이 아니라, 하나의 데이터로 들어와서 엉뚱한 데이터가 추가된다.
(1) 컬럼명을 인덱스로 지정
index_col='컬럼명'
df1 = pd.read_csv('./result/temp.csv', names=['No', '시도', '구분', '인구', '면적'], index_col='No')
df1
| 시도 | 구분 | 인구 | 면적 | |
|---|---|---|---|---|
| No | ||||
| NaN | 시도 | 구분 | 인구 | 면적 |
| 0.0 | 서울 | 특별시 | 999만 | 600.9 |
| 1.0 | 경기 | 도 | 1300만 | 10171.0 |
| 2.0 | 인천 | 광역시 | 400만 | 1234.5 |
| 3.0 | 부산 | 광역시 | 600만 | 747.8 |
| 4.0 | 대전 | 광역시 | 300만 | 459.1 |
(2) 불필요한 행 제외하고 로딩하기
skiprows=[숫자]
df1 = pd.read_csv('./result/temp.csv', names=['No', '시도', '구분', '인구', '면적'], index_col='No', skiprows=[0])
df1
| 시도 | 구분 | 인구 | 면적 | |
|---|---|---|---|---|
| No | ||||
| 0 | 서울 | 특별시 | 999만 | 600.9 |
| 1 | 경기 | 도 | 1300만 | 10171.0 |
| 2 | 인천 | 광역시 | 400만 | 1234.5 |
| 3 | 부산 | 광역시 | 600만 | 747.8 |
| 4 | 대전 | 광역시 | 300만 | 459.1 |
출력행수 지정
Q. 3개의 행만 가져오고 싶을 때
nrows=숫자
df1 = pd.read_csv('./result/temp.csv', names=['No', '시도', '구분', '인구', '면적'], index_col='No', skiprows=[0], nrows=3)
df1
| 시도 | 구분 | 인구 | 면적 | |
|---|---|---|---|---|
| No | ||||
| 0 | 서울 | 특별시 | 999만 | 600.9 |
| 1 | 경기 | 도 | 1300만 | 10171.0 |
| 2 | 인천 | 광역시 | 400만 | 1234.5 |
엑셀 파일 로딩하기
df2 = pd.read_excel('./data/인구주택총조사2015.xlsx', index_col='행정구역별')
df2
| 총인구 | 남자 | 여자 | 내국인계 | 내국인_남자 | 내국인_여자 | 외국인계 | 외국인_남자 | 외국인_여자 | 가구계 | 일반가구 | 집단가구 | 외국인가구 | 주택계 | 단독주택 | 아파트 | 연립주택 | 다세대주택 | 비거주용건물내주택 | 주택이외의거처 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 행정구역별 | ||||||||||||||||||||
| 전국 | 51069375 | 25608502 | 25460873 | 49705663 | 24819839 | 24885824 | 1363712 | 788663 | 575049 | 19560603 | 19111030 | 16464 | 433109 | 16367006 | 3973961 | 9806062 | 485349 | 1898090 | 203544 | 607195 |
| 읍부 | 4616802 | 2360708 | 2256094 | 4467697 | 2262853 | 2204844 | 149105 | 97855 | 51250 | 1737415 | 1695508 | 2189 | 39718 | 1614808 | 544351 | 864404 | 66387 | 112764 | 26902 | 49554 |
| 면부 | 4774878 | 2455898 | 2318980 | 4546520 | 2291860 | 2254660 | 228358 | 164038 | 64320 | 1981033 | 1927621 | 4284 | 49128 | 1982064 | 1524970 | 334810 | 31485 | 61366 | 29433 | 78036 |
| 동부 | 41677695 | 20791896 | 20885799 | 40691446 | 20265126 | 20426320 | 986249 | 526770 | 459479 | 15842155 | 15487901 | 9991 | 344263 | 12770134 | 1904640 | 8606848 | 387477 | 1723960 | 147209 | 479605 |
| 서울특별시 | 9904312 | 4859535 | 5044777 | 9567196 | 4694317 | 4872879 | 337116 | 165218 | 171898 | 3914820 | 3784490 | 2261 | 128069 | 2793244 | 355039 | 1636896 | 117235 | 654372 | 29702 | 150951 |
| 부산광역시 | 3448737 | 1701347 | 1747390 | 3404667 | 1675339 | 1729328 | 44070 | 26008 | 18062 | 1348315 | 1335900 | 686 | 11729 | 1164352 | 225697 | 738068 | 32120 | 154253 | 14214 | 50810 |
| 대구광역시 | 2466052 | 1228511 | 1237541 | 2436770 | 1211219 | 1225551 | 29282 | 17292 | 11990 | 937573 | 928528 | 574 | 8471 | 738100 | 155801 | 509068 | 9381 | 53098 | 10752 | 15304 |
| 인천광역시 | 2890451 | 1455017 | 1435434 | 2822601 | 1414793 | 1407808 | 67850 | 40224 | 27626 | 1066297 | 1045417 | 713 | 20167 | 942244 | 102914 | 577346 | 21589 | 232346 | 8049 | 39964 |
| 광주광역시 | 1502881 | 748867 | 754014 | 1481289 | 736656 | 744633 | 21592 | 12211 | 9381 | 573181 | 567157 | 438 | 5586 | 486527 | 88401 | 376731 | 7396 | 8517 | 5482 | 10625 |
| 대전광역시 | 1538394 | 772243 | 766151 | 1519314 | 763310 | 756004 | 19080 | 8933 | 10147 | 588395 | 582504 | 420 | 5471 | 468885 | 81292 | 338250 | 10068 | 34151 | 5124 | 10676 |
| 울산광역시 | 1166615 | 606924 | 559691 | 1136755 | 587603 | 549152 | 29860 | 19321 | 10539 | 434058 | 423412 | 239 | 10407 | 357674 | 66190 | 253010 | 7564 | 24585 | 6325 | 7444 |
| 세종특별자치시 | 204088 | 103210 | 100878 | 199617 | 100455 | 99162 | 4471 | 2755 | 1716 | 76419 | 75219 | 65 | 1135 | 81130 | 15696 | 62274 | 997 | 1499 | 664 | 2112 |
| 경기도 | 12479061 | 6309661 | 6169400 | 12026429 | 6039800 | 5986629 | 452632 | 269861 | 182771 | 4537581 | 4384742 | 3879 | 148960 | 3693557 | 498250 | 2502091 | 121960 | 538971 | 32285 | 163742 |
| 강원도 | 1518040 | 768241 | 749799 | 1499734 | 758601 | 741133 | 18306 | 9640 | 8666 | 611578 | 606117 | 788 | 4673 | 569899 | 230825 | 297005 | 20233 | 11037 | 10799 | 12283 |
| 충청북도 | 1589347 | 805377 | 783970 | 1548589 | 779961 | 768628 | 40758 | 25416 | 15342 | 613004 | 601856 | 814 | 10334 | 556951 | 204614 | 308352 | 15975 | 18382 | 9628 | 13852 |
| 충청남도 | 2107802 | 1078310 | 1029492 | 2036720 | 1034139 | 1002581 | 71082 | 44171 | 26911 | 816247 | 796185 | 1107 | 18955 | 754372 | 304281 | 382323 | 20096 | 37071 | 10601 | 23297 |
| 전라북도 | 1834114 | 915729 | 918385 | 1804184 | 899308 | 904876 | 29930 | 16421 | 13509 | 726572 | 717311 | 834 | 8427 | 687103 | 282928 | 364712 | 14980 | 14153 | 10330 | 13926 |
| 전라남도 | 1799044 | 900967 | 898077 | 1764433 | 879860 | 884573 | 34611 | 21107 | 13504 | 730743 | 720612 | 933 | 9198 | 747621 | 404904 | 306661 | 14187 | 9915 | 11954 | 20253 |
| 경상북도 | 2680294 | 1351037 | 1329257 | 2622729 | 1314196 | 1308533 | 57565 | 36841 | 20724 | 1078479 | 1062724 | 1312 | 14443 | 995385 | 457157 | 449154 | 27799 | 44533 | 16742 | 26036 |
| 경상남도 | 3334524 | 1698737 | 1635787 | 3244163 | 1634407 | 1609756 | 90361 | 64330 | 26031 | 1282617 | 1258487 | 1176 | 22954 | 1134738 | 416364 | 641589 | 24944 | 35701 | 16140 | 36605 |
| 제주특별자치도 | 605619 | 304789 | 300830 | 590473 | 295875 | 294598 | 15146 | 8914 | 6232 | 224724 | 220369 | 225 | 4130 | 195224 | 83608 | 62532 | 18825 | 25506 | 4753 | 9315 |
컬럼 지정 (컬럼의 종류가 너무 많은데 필요한 부분이 작은 경우에 사용한다)
usecols='엑셀컬럼명:엑셀컬럼명'
df2 = pd.read_excel('./data/인구주택총조사2015.xlsx', usecols='C:K', nrows=10)
df2
| 남자 | 여자 | 내국인계 | 내국인_남자 | 내국인_여자 | 외국인계 | 외국인_남자 | 외국인_여자 | 가구계 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 25608502 | 25460873 | 49705663 | 24819839 | 24885824 | 1363712 | 788663 | 575049 | 19560603 |
| 1 | 2360708 | 2256094 | 4467697 | 2262853 | 2204844 | 149105 | 97855 | 51250 | 1737415 |
| 2 | 2455898 | 2318980 | 4546520 | 2291860 | 2254660 | 228358 | 164038 | 64320 | 1981033 |
| 3 | 20791896 | 20885799 | 40691446 | 20265126 | 20426320 | 986249 | 526770 | 459479 | 15842155 |
| 4 | 4859535 | 5044777 | 9567196 | 4694317 | 4872879 | 337116 | 165218 | 171898 | 3914820 |
| 5 | 1701347 | 1747390 | 3404667 | 1675339 | 1729328 | 44070 | 26008 | 18062 | 1348315 |
| 6 | 1228511 | 1237541 | 2436770 | 1211219 | 1225551 | 29282 | 17292 | 11990 | 937573 |
| 7 | 1455017 | 1435434 | 2822601 | 1414793 | 1407808 | 67850 | 40224 | 27626 | 1066297 |
| 8 | 748867 | 754014 | 1481289 | 736656 | 744633 | 21592 | 12211 | 9381 | 573181 |
| 9 | 772243 | 766151 | 1519314 | 763310 | 756004 | 19080 | 8933 | 10147 | 588395 |
텍스트파일 읽어오기¶
텍스트파일 읽어오기 (ex. read_csv 이용)
미리 엑셀파일에서 5줄 복사해서 메모장에 넣고 (탭구분상태)로 저장한다.
df_txt = pd.read_table('./data/TextData.txt', encoding='cp949', index_col='행정구역별')
df_txt
| 총인구 | 남자 | 여자 | 내국인계 | 내국인_남자 | |
|---|---|---|---|---|---|
| 행정구역별 | |||||
| 전국 | 51069375 | 25608502 | 25460873 | 49705663 | 24819839 |
| 읍부 | 4616802 | 2360708 | 2256094 | 4467697 | 2262853 |
| 면부 | 4774878 | 2455898 | 2318980 | 4546520 | 2291860 |
| 동부 | 41677695 | 20791896 | 20885799 | 40691446 | 20265126 |
JSON 파일 읽어오기¶
import json
df_json = json.load(open('./data/JsonData.json'))
df_json
{'kind1': 'koreanfood',
'region': ['nosong', 'bibim', 'jungsung'],
'food_name': {'best-of-best': 'bibimbab', 'one-of-best': 'bulgogi'}}df1 = pd.read_json('data/JsonData.json',orient='index')
df1
| 0 | |
|---|---|
| kind1 | koreanfood |
| region | [nosong, bibim, jungsung] |
| food_name | {'best-of-best': 'bibimbab', 'one-of-best': 'b... |
2. 판다스 파일 읽기 (2)
인터넷 상의 데이타 읽기¶
-
Url 상의 csv 읽기 : pandas.read_csv(url)
-
크롤링하여 읽기
requests / Selenium 라이브러리 활용pandas.read_html(url, .. ) : 내부적으로 requests 라이브러리 사용 -
pandas-datareader 라이브러리
내부적으로 requests 라이브러리 사용버전에 따라 오류 발생 ` Google Finance/Yahoo Finance 등에서 데이타 지원 -> 연결이 안될 수도 있음
[참고] Kosdaq 종목코드 CSV URL : https://goo.gl/3p3dSG
- https://gist.githubusercontent.com/allieus/5ce98166166d06ee9060e6a261e812dc/raw
- 위 주소를 pandas.read_csv(여기)에 붙이기
[참고] Kospi 종목코드 CSV URL : https://goo.gl/aUHznC
- https://gist.githubusercontent.com/allieus/733725662c644ab56c9db9d3cdf77ed1/raw(1) read_csv()¶
url로 접속해보면 , 로 데이터를 구분하고 있으므로, read_csv( )로 읽어올 수 있다.
import pandas as pd
df1 = pd.read_csv('https://gist.githubusercontent.com/allieus/733725662c644ab56c9db9d3cdf77ed1/raw')
df1.head()
| 종목명 | 종목코드 | |
|---|---|---|
| 0 | 미원에스씨 | 268280 |
| 1 | 경동도시가스 | 267290 |
| 2 | 넷마블게임즈 | 251270 |
| 3 | 아이엔지생명 | 79440 |
| 4 | 현대건설기계 | 267270 |
(2) pandas.read_html()
-
웹페이지 크롤링을 쉽게 도와주는 만능 라이브러리 X (아님)
-
웹 페이지 상의 HTML table을 한번에 로딩하기 위한 목적임
그러나 데이터 외에 다른 문자열이 있으면 곤란
→ 요즘은 동적 테이블을 사용하기 때문에 가져오지 못 하는 경우가 더 많아서 무용지물 됨ㅋ
(3) pandas-datareader 라이브러리¶
` 설치 필요
` 최신버전 업그레이드 필수
` pip install --upgrade pandas-datareader
` Anaconda Prompt에서 확인 가능(반드시 관리자 권한으로 실행) : conda install pandas-datareader
` Jupyter 에서 !pip install --upgrade pandas-datareaderAnaconda Prompt 에 입력하는 대신, 느낌표 ! 를 사용하여 운영체제 명령어를 사용할 수 있다.
#!pip install --upgrade pandas-datareader
import pandas_datareader as pdr
pdr.get_data_yahoo('네이버주식코드', '시작일', '종료일')로 데이터를 가져올 수 있다.
pdr.get_data_yahoo('035420.KS', '2021-01-01', '2021-02-02')
| High | Low | Open | Close | Volume | Adj Close | |
|---|---|---|---|---|---|---|
| Date | ||||||
| 2021-01-04 | 294000 | 285500 | 291500 | 293000 | 947178 | 293000 |
| 2021-01-05 | 292500 | 286500 | 291500 | 292500 | 912657 | 292500 |
| 2021-01-06 | 300500 | 289500 | 292500 | 290000 | 1375856 | 290000 |
| 2021-01-07 | 292000 | 286500 | 288500 | 289500 | 1155734 | 289500 |
| 2021-01-08 | 312000 | 290000 | 293500 | 312000 | 3175396 | 312000 |
| 2021-01-11 | 323500 | 301000 | 320000 | 309000 | 2765169 | 309000 |
| 2021-01-12 | 308500 | 292500 | 305000 | 304000 | 1573299 | 304000 |
| 2021-01-13 | 317500 | 304000 | 306000 | 314000 | 1894304 | 314000 |
| 2021-01-14 | 326000 | 314000 | 318500 | 318000 | 1548585 | 318000 |
| 2021-01-15 | 323000 | 305500 | 320500 | 306000 | 1106810 | 306000 |
| 2021-01-18 | 308500 | 300000 | 304500 | 300500 | 864969 | 300500 |
| 2021-01-19 | 310500 | 299500 | 303500 | 308000 | 880238 | 308000 |
| 2021-01-20 | 313500 | 302000 | 313500 | 308000 | 885472 | 308000 |
| 2021-01-21 | 326000 | 316000 | 316500 | 322500 | 1941446 | 322500 |
| 2021-01-22 | 350000 | 326000 | 332000 | 343500 | 3303950 | 343500 |
| 2021-01-25 | 353000 | 340000 | 349000 | 349000 | 1593848 | 349000 |
| 2021-01-26 | 351000 | 338000 | 350500 | 342000 | 1247284 | 342000 |
| 2021-01-27 | 352000 | 339500 | 347000 | 341500 | 1149246 | 341500 |
| 2021-01-28 | 366000 | 335000 | 336000 | 355000 | 2285696 | 355000 |
| 2021-01-29 | 362000 | 340500 | 362000 | 343000 | 1607894 | 343000 |
| 2021-02-01 | 352500 | 341500 | 346500 | 348000 | 988630 | 348000 |
| 2021-02-02 | 370000 | 353000 | 358000 | 369500 | 828511 | 369500 |
3. 판다스 문자열 연습
문자열 처리¶
- 파이썬의 기본 문자열 메소드
- 정규표현식 문자열 처리
- pandas의 문자열 메소드
(1) 파이썬 기본 문자 관련 메소드
+ str :
+ upper / lower :대문자로 변경 / 소문자로 변경
+ count : 문자열 출현 횟수 반환
+ find : 찾고자 하는 단어의 첫글자 위치를 반환 ( 없으면 -1 반환)
+ replace : 문자열을 다른 문자열로 치환
+ strip / rstrip / lstrip : 문자열 좌우 공백 제거
+ split : 구분자 기준으로 단어 분리
+ ljust / rjust : 문자열 왼쪽(오른쪽)정렬하고 남은 길이만큼 공백처리하여 반환
(2) 정규표현식 문자열 처리 – re 모듈
^ 문자열 시작
[ ] 문자집합이나 범위
$ 문자열 종료
{ } 횟수 또는 범위
* 0개 이상
( ) 소괄호 안의 문자를 하나의 문자로 인식
+ 1개 이상
| or 연산자 역할
? 0개 이거나 1개
. 아무 문자
\s 공백문자
\d 숫자[0-9]와 동일
\S 공백문자가 아닌 나머지 문자
\D 숫자를 제외한 모든 문자
\w 알파벳이나 숫자
\특수문자 해당 특수문자
\W 알파벳이나 숫자를 제외한 문자
(?!) 대소문자 구분하지 않음
(3) pandas에서 text 분석을 위한 Series의 문자열 함수
- 데이터 분석을 위해 문자열 정제작업을 간결하게 처리하는 메소드 제공
cat : 선택적인 구분자와 함계 요소별 문자열 이어붙임
contains : 문자열이 패턴이나 정규표현식을 포함하는지 True/False 배열을 반환
count : 일치하는 패턴의 개수를 반환
findall : 각 문자열에 대해 일치하는 정규표현식의 전체 목록을 구함
join : Series외 각 요소를 주어진 구분자로 연결
match : 주어진 정규표현식으로 각 요소에 대한 re.match를 수행하여 일치하는 그룹의 리스트를 반환
get : i번째 요소를 반황음원차트 데이타셋¶
(1) 곡명(name)에서 10글자만 추출
(2) 곡명을 단어들 중 첫 번째 단어만 추출
(3) W로 시작하는 artist_name 추출
(4) album_name에 'LOVE'이라는 단어가 들어있는 데이타 추출
(5) album_name을 5글자로 줄이고 그 뒤는 ... 표시하여 album_name_ax 컬럼을 추가
(6) artist_name에서 ( 또는 - 앞의 단어까지만 추출
import pandas as pd
import re
df = pd.read_excel('data/top100.xlsx', index_col='id')
df
| album_name | artist_name | name | 좋아요 | |
|---|---|---|---|---|
| id | ||||
| 31093710 | Red Diary Page.2 | 볼빨간사춘기 | 여행 | 124968 |
| 31085237 | LOVE YOURSELF 轉 `Tear` | 방탄소년단 | FAKE LOVE | 200654 |
| 31113240 | 1÷χ=1 (UNDIVIDED) | Wanna One (워너원) | 켜줘 (Light) | 93035 |
| 31113241 | 1÷χ=1 (UNDIVIDED) | Wanna One (워너원) - 트리플포지션 | 캥거루 (Kangaroo) (Prod. ZICO) | 79320 |
| 31113243 | 1÷χ=1 (UNDIVIDED) | Wanna One (워너원) - 더힐 | 모래시계 (Prod. 헤이즈) | 67872 |
| ... | ... | ... | ... | ... |
| 31123659 | `The Story of Light` EP.2 - The 6th Album | SHINee (샤이니) | 독감 (Who Waits For Love) | 12730 |
| 30086173 | LIFE IS BEAUTY FULL | 문문 (MoonMoon) | 비행운 | 202347 |
| 30383758 | 종현 소품집 `이야기 Op.2` | 종현 (JONGHYUN) | Lonely (Feat. 태연) | 180606 |
| 30481578 | 마지막처럼 | BLACKPINK | 마지막처럼 | 159147 |
| 30380953 | Illuminate (New Deluxe Ver.) | Shawn Mendes | There`s Nothing Holdin` Me Back | 107309 |
100 rows × 4 columns
(1) 곡명(name)에서 10글자만 추출
pd.DataFrame(df.name.str[:10])
| name | |
|---|---|
| id | |
| 31093710 | 여행 |
| 31085237 | FAKE LOVE |
| 31113240 | 켜줘 (Light) |
| 31113241 | 캥거루 (Kanga |
| 31113243 | 모래시계 (Prod |
| ... | ... |
| 31123659 | 독감 (Who Wa |
| 30086173 | 비행운 |
| 30383758 | Lonely (Fe |
| 30481578 | 마지막처럼 |
| 30380953 | There`s No |
100 rows × 1 columns
(2) 곡명을 단어로 나눠서 첫 번째 단어만 추출
df.name.str.split(' ').str[0:1]
id
31093710 [여행]
31085237 [FAKE]
31113240 [켜줘]
31113241 [캥거루]
31113243 [모래시계]
...
31123659 [독감]
30086173 [비행운]
30383758 [Lonely]
30481578 [마지막처럼]
30380953 [There`s]
Name: name, Length: 100, dtype: object(3) W로 시작하는 artist_name 추출
pd.DataFrame(df.artist_name[df.artist_name.str.contains(r'^(W)')])
| artist_name | |
|---|---|
| id | |
| 31113240 | Wanna One (워너원) |
| 31113241 | Wanna One (워너원) - 트리플포지션 |
| 31113243 | Wanna One (워너원) - 더힐 |
| 30960341 | Wanna One (워너원) |
| 31113242 | Wanna One (워너원) - 린온미 |
| 31113244 | Wanna One (워너원) - 남바완 |
| 30568338 | Wanna One (워너원) |
| 30725482 | Wanna One (워너원) |
| 30930312 | Wanna One (워너원) |
| 30997649 | WINNER |
| 30341745 | WINNER |
(4) album_name에 'LOVE'이라는 단어가 들어있는 데이타 추출
df[df.album_name.str.contains(r'LOVE')]
| album_name | artist_name | name | 좋아요 | |
|---|---|---|---|---|
| id | ||||
| 31085237 | LOVE YOURSELF 轉 `Tear` | 방탄소년단 | FAKE LOVE | 200654 |
| 31085238 | LOVE YOURSELF 轉 `Tear` | 방탄소년단 | 전하지 못한 진심 (Feat. Steve Aoki) | 129126 |
| 30637982 | LOVE YOURSELF 承 `Her` | 방탄소년단 | DNA | 301340 |
| 31085244 | LOVE YOURSELF 轉 `Tear` | 방탄소년단 | Anpanman | 107561 |
| 31085243 | LOVE YOURSELF 轉 `Tear` | 방탄소년단 | Airplane pt.2 | 102741 |
| 31085240 | LOVE YOURSELF 轉 `Tear` | 방탄소년단 | 낙원 | 102395 |
| 31085242 | LOVE YOURSELF 轉 `Tear` | 방탄소년단 | Magic Shop | 106310 |
| 31085241 | LOVE YOURSELF 轉 `Tear` | 방탄소년단 | Love Maze | 101755 |
| 31085239 | LOVE YOURSELF 轉 `Tear` | 방탄소년단 | 134340 | 102354 |
| 31085245 | LOVE YOURSELF 轉 `Tear` | 방탄소년단 | So What | 93015 |
| 31085236 | LOVE YOURSELF 轉 `Tear` | 방탄소년단 | Intro : Singularity | 94973 |
| 31085246 | LOVE YOURSELF 轉 `Tear` | 방탄소년단 | Outro : Tear | 88929 |
| 31113142 | FAKE LOVE (Rocking Vibe Mix) | 방탄소년단 | FAKE LOVE (Rocking Vibe Mix) | 51784 |
# 기타
df['album_name'].str.strip() # 좌우 공백제거
df['album_name'].str.lstrip() # 좌 공백제거
df['album_name'].str.rstrip() # 우 공백제거
df['album_name'].str.rstrip(')') # 우측의 ) 제거
df['album_name'].str.lower() # 소문자로
df['album_name'].str.upper() # 대문자로
df['album_name'].str.replace('(UNDIVIDED)','테스트')
df['album_name'].str.replace('(UNDIVIDED)','') # 지우고 싶을 때 - ()는 남아있는데???
id
31093710 Red Diary Page.2
31085237 LOVE YOURSELF 轉 `Tear`
31113240 1÷χ=1 ()
31113241 1÷χ=1 ()
31113243 1÷χ=1 ()
...
31123659 `The Story of Light` EP.2 - The 6th Album
30086173 LIFE IS BEAUTY FULL
30383758 종현 소품집 `이야기 Op.2`
30481578 마지막처럼
30380953 Illuminate (New Deluxe Ver.)
Name: album_name, Length: 100, dtype: object(5) album_name을 10글자로 줄이고 그 뒤는 ... 표시하여 album_name_ax 컬럼을 추가
[힌트] 함수 선언하여 apply 함수이용 가능
def temp(df):
temp = df['album_name'][:10]
if len(df['album_name'])>10:
temp = temp + '...'
return temp
df['album_name_ax'] = df.apply(temp, axis=1)
df
| album_name | artist_name | name | 좋아요 | album_name_ax | |
|---|---|---|---|---|---|
| id | |||||
| 31093710 | Red Diary Page.2 | 볼빨간사춘기 | 여행 | 124968 | Red Diary ... |
| 31085237 | LOVE YOURSELF 轉 `Tear` | 방탄소년단 | FAKE LOVE | 200654 | LOVE YOURS... |
| 31113240 | 1÷χ=1 (UNDIVIDED) | Wanna One (워너원) | 켜줘 (Light) | 93035 | 1÷χ=1 (UND... |
| 31113241 | 1÷χ=1 (UNDIVIDED) | Wanna One (워너원) - 트리플포지션 | 캥거루 (Kangaroo) (Prod. ZICO) | 79320 | 1÷χ=1 (UND... |
| 31113243 | 1÷χ=1 (UNDIVIDED) | Wanna One (워너원) - 더힐 | 모래시계 (Prod. 헤이즈) | 67872 | 1÷χ=1 (UND... |
| ... | ... | ... | ... | ... | ... |
| 31123659 | `The Story of Light` EP.2 - The 6th Album | SHINee (샤이니) | 독감 (Who Waits For Love) | 12730 | `The Story... |
| 30086173 | LIFE IS BEAUTY FULL | 문문 (MoonMoon) | 비행운 | 202347 | LIFE IS BE... |
| 30383758 | 종현 소품집 `이야기 Op.2` | 종현 (JONGHYUN) | Lonely (Feat. 태연) | 180606 | 종현 소품집 `이야... |
| 30481578 | 마지막처럼 | BLACKPINK | 마지막처럼 | 159147 | 마지막처럼 |
| 30380953 | Illuminate (New Deluxe Ver.) | Shawn Mendes | There`s Nothing Holdin` Me Back | 107309 | Illuminate... |
100 rows × 5 columns
[추가] 톱 100 안에 가수별 곡명 수¶
4. 판다스 시각화가 필요한 이유
이 페이지는 자세한 분석을 위한 페이지가 아닙니다.
시각화를 해야하는 이유를 보여주기 위한 페이지입니다.
(1) anscombe 의 데이터를 한 눈에 확인하기 어렵다.
import seaborn
anscombe = seaborn.load_dataset('anscombe')
anscombe
| dataset | x | y | |
|---|---|---|---|
| 0 | I | 10.0 | 8.04 |
| 1 | I | 8.0 | 6.95 |
| 2 | I | 13.0 | 7.58 |
| 3 | I | 9.0 | 8.81 |
| 4 | I | 11.0 | 8.33 |
| 5 | I | 14.0 | 9.96 |
| 6 | I | 6.0 | 7.24 |
| 7 | I | 4.0 | 4.26 |
| 8 | I | 12.0 | 10.84 |
| 9 | I | 7.0 | 4.82 |
| 10 | I | 5.0 | 5.68 |
| 11 | II | 10.0 | 9.14 |
| 12 | II | 8.0 | 8.14 |
| 13 | II | 13.0 | 8.74 |
| 14 | II | 9.0 | 8.77 |
| 15 | II | 11.0 | 9.26 |
| 16 | II | 14.0 | 8.10 |
| 17 | II | 6.0 | 6.13 |
| 18 | II | 4.0 | 3.10 |
| 19 | II | 12.0 | 9.13 |
| 20 | II | 7.0 | 7.26 |
| 21 | II | 5.0 | 4.74 |
| 22 | III | 10.0 | 7.46 |
| 23 | III | 8.0 | 6.77 |
| 24 | III | 13.0 | 12.74 |
| 25 | III | 9.0 | 7.11 |
| 26 | III | 11.0 | 7.81 |
| 27 | III | 14.0 | 8.84 |
| 28 | III | 6.0 | 6.08 |
| 29 | III | 4.0 | 5.39 |
| 30 | III | 12.0 | 8.15 |
| 31 | III | 7.0 | 6.42 |
| 32 | III | 5.0 | 5.73 |
| 33 | IV | 8.0 | 6.58 |
| 34 | IV | 8.0 | 5.76 |
| 35 | IV | 8.0 | 7.71 |
| 36 | IV | 8.0 | 8.84 |
| 37 | IV | 8.0 | 8.47 |
| 38 | IV | 8.0 | 7.04 |
| 39 | IV | 8.0 | 5.25 |
| 40 | IV | 19.0 | 12.50 |
| 41 | IV | 8.0 | 5.56 |
| 42 | IV | 8.0 | 7.91 |
| 43 | IV | 8.0 | 6.89 |
(2) dataset 컬럼의 값에 따라 그룹을 나눈다.
여전히 각 값의 범위를 파악하진 못한다.
# dataset의 값이 I, II, III, IV 별로 추출
dataset_1 = anscombe[ anscombe['dataset']=='I']
dataset_2 = anscombe[ anscombe['dataset']=='II']
dataset_3 = anscombe[ anscombe['dataset']=='III']
dataset_4 = anscombe[ anscombe['dataset']=='IV']
(3) 각각의 dataset의 통계치 확인하면 --- 평균, 분산 유사하다.
dataset_1.mean()
x 9.000000
y 7.500909
dtype: float64x, y = dataset_1.mean()
print('x={0} y={1}'.format(x, y))
x, y = dataset_2.mean()
print('x={0} y={1}'.format(x, y))
x, y = dataset_3.mean()
print('x={0} y={1}'.format(x, y))
x, y = dataset_4.mean()
print('x={0} y={1}'.format(x, y))
x, y = dataset_1.var()
print('x={0} y={1}'.format(x, y))
x, y = dataset_2.var()
print('x={0} y={1}'.format(x, y))
x, y = dataset_3.var()
print('x={0} y={1}'.format(x, y))
x, y = dataset_4.var()
print('x={0} y={1}'.format(x, y))
x=9.0 y=7.500909090909093
x=9.0 y=7.500909090909091
x=9.0 y=7.500000000000001
x=9.0 y=7.50090909090909
x=11.0 y=4.127269090909091
x=11.0 y=4.127629090909091
x=11.0 y=4.12262
x=11.0 y=4.12324909090909
시각화하기 - 하나씩 출력하여 데이타 구조가 다름을 확인
import matplotlib.pyplot as plt
plt.plot(dataset_1['x'], dataset_1['y'])
plt.plot(dataset_1['x'], dataset_1['y'], 'o')
plt.plot(dataset_2['x'], dataset_2['y'], 'o')
plt.plot(dataset_3['x'], dataset_3['y'], 'o')
plt.plot(dataset_4['x'], dataset_4['y'], 'o')
[<matplotlib.lines.Line2D at 0x1ec6dc974f0>]
[결론] 평균, 분산 등의 수치가 같아도 그래프 형태로 확인하면 다른 데이타임을 알 수 있다
fig = plt.figure() # 1-전체 그래프의 기본 틀
axes1 = fig.add_subplot(2,2,1) # 2-그래프를 넣을 그래프 격자
axes2 = fig.add_subplot(2,2,2)
axes3 = fig.add_subplot(2,2,3)
axes4 = fig.add_subplot(2,2,4)
axes1.plot(dataset_1['x'], dataset_1['y'], 'o') # 3-격자에 그래프 추가
axes2.plot(dataset_2['x'], dataset_2['y'], 'o')
axes3.plot(dataset_3['x'], dataset_3['y'], 'o')
axes4.plot(dataset_4['x'], dataset_4['y'], 'o')
# 안나오면 fig 입력하여 확인
[<matplotlib.lines.Line2D at 0x1ec6e067640>]

5. 판다스 한글처리
%matplotlib inline
import matplotlib.pyplot as plt
판다스 한글등록¶
# 한글등록
from matplotlib import font_manager, rc # rc : resource
# 추가설정 - 폰트를 변경하면 -표시가 ㅁ으로 변경되기에 '-'를 변경하지 않도록 지정
plt.rcParams['axes.unicode_minus']=False
fong_loc = "c:/Windows/Fonts/malgun.ttf" # 글꼴 경로
font_name = font_manager.FontProperties(fname=fong_loc).get_name()
# print(font_name) # 폰트매니저를 통해 인식하고 있는 글꼴 이름을 가져온다
rc('font', family=font_name) # 리소스에 글꼴을 등록
간단한 한글등록(*)¶
from matplotlib import font_manager, rc
plt.rcParams['axes.unicode_minus']=False # 추가설정 : 폰트를 변경하면 -표시가 ㅁ으로 변경되기에 '-'를 변경하지 않도록 지정
rc('font', family='Malgun Gothic')
[참고] 폰트종류 볼 때¶
font_manager.fontManager.ttflist
6. 판다스 제공
1. Series 의 plot()¶
%matplotlib inline
import matplotlib.pyplot as plt
판다스 그래프 : Series의 plot()
s = Series([1.5, 2.3, 0.9], index=['no1','no2','no3'])
print(type(s));
s.plot(kind='bar');
<class 'pandas.core.series.Series'>

위의 판다스 제공 그래프와 matplotlib 그래프 비교¶
# 한글처리
from pandas import Series
from matplotlib import font_manager, rc
plt.rcParams['axes.unicode_minus']=False
rc('font', family='Malgun Gothic')
s = Series([1.5, 2.3, 0.9], index=['일','이','삼'])
splot = s.plot.bar();
splot.set_xlabel('데이터');
splot.set_ylabel('값');
splot.set_title('샘플 그래프');

2. DataFrame 그래프¶
from pandas import DataFrame
import numpy as np
# 데이타프레임에서 시각화 작업
df=DataFrame(np.random.randn(10, 4), # 난수 10개를 4번
columns=['level','step','cnt','temp'],
index=np.arange(0,100,10)) ; # np.arange(0,100,10)
df.plot();

[참고] 데이타사이언스스쿨 > Pandas의 시각화 기능
https://datascienceschool.net/view-notebook/372443a5d90a46429c6459bba8b4342c/
7. 판다스 plot
기본적인 그래프¶
- 세미콜론 시, 그래프 위에 지저분한 글씨 (객체 표시) 안 뜸
import matplotlib.pyplot as plt
data = [10, 15, 19, 30, 20]
plt.plot(data);

→ 내가 입력한 데이터는 y축으로 표시된다.
본래 콘솔에서 판다스를 사용하여 시각화 할 때는 다음 차례대로 작성해야 했다.
- 그래프 틀(영역)을 만들기
- 그래프 그리기
3.그래프 보여주기
import matplotlib.pyplot as plt
data = [10, 15, 19, 30, 20]
plt.figure()
plt.plot(data)
plt.show()
# 별도로 영역 크기를 지정하고자 할 경우
plt.figure(figsize=(20,10))
plt.plot(data)
plt.show()
x축, y축, 제목 지정하기
- plt.plot( ) 안에 입력되는 순서에 따라 지정된다.
import matplotlib.pyplot as plt
data = [10, 15, 19, 30, 20]
step = ['one', 'two', 'three', 'four', 'five']
plt.plot(step, data); # -- x축 step, y축 data
plt.title('Sample');
plt.xlabel('time');
plt.ylabel('temp');
plt.show()

바닥판 모양을 그리고자 할 경우
import matplotlib.pyplot as plt
data = [10, 15, 19, 30, 20]
step = ['one', 'two', 'three', 'four', 'five']
plt.plot(step, data);
plt.grid();

속성 : linestyle , color , marker
plt.plot(step, data, linestyle='dashed', color='blue', marker='o');

속성 축약
plt.plot(step, data, 'bo--');
[참고] 선의 두께와 선의 색을 지정
- lw의 기본값은 1
- 선 색 {'b','g','r','c','m','y', 'k', 'w' }
plt.plot(step, data, linestyle='dashed', color='blue', marker='o', lw=3);

마커속성
plt.plot(step, data, linestyle='dashed', color='blue', marker='o', lw=3, markerfacecolor='red', markersize=12);

8. 판다스 시각화 선과 색, 범례
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
0. 플롯 스타일*
plt.style.use('classic')
plt.style.use('seaborn-whitegrid')
x = np.linspace(0, 10, 100) # 0 ~ 10까지의 수 중 100개를 균등하게 추출해준다.
x
plt.plot(np.sin(x));

1. 색상지정
plt.plot(np.sin(x-1), color='blue');
plt.plot(np.sin(x-2), color='r');
plt.plot(np.sin(x-3), color='#FF8822');
plt.plot(np.sin(x-4), color='chartreuse'); # HTML 색상 이름표 참고
plt.plot(np.sin(x-5), color='0.75'); # 검정 0 ~ 1 옅은 회색
plt.plot(np.sin(x-6), color=( .9 , 1.0 , .3 ) ); # 튜플 형태로 RGB 입력할 때는 0 ~ 1 사이의 수로 지정

2. 선스타일
plt.plot(np.sin(x), linestyle='solid');
plt.plot(np.sin(x-1), linestyle='dashed');
plt.plot(np.sin(x-2), linestyle='dashdot');
plt.plot(np.sin(x-3), linestyle='dotted');
# 또는
plt.plot(np.sin(x), linestyle='-');
plt.plot(np.sin(x-1), linestyle='--');
plt.plot(np.sin(x-2), linestyle='-.');
plt.plot(np.sin(x-3), linestyle=':');

r(red) g(green) b(blue) c(cyan) m(magenta) y(yellow) k(black)¶
3. 선과 스타일을 간결하게 (대략 읽는 수준으로 )
plt.plot(np.sin(x), 'g-'); # 초록색 solid
plt.plot(np.sin(x-1), '--c'); # 시안색 dashed
plt.plot(np.sin(x-2), '-.k'); # 검은색 dashdot
plt.plot(np.sin(x-3), ':r'); # 빨간색 dotted

4. 범례
plt.plot(np.sin(x), 'g-', label='first'); # 초록색 solid
plt.plot(np.sin(x-1), '--c', label='second'); # 시안색 dashed
plt.plot(np.sin(x-2), '-.k', label='third'); # 검은색 dashdot
plt.plot(np.sin(x-3), ':r', label='fourth'); # 빨간색 dotted
plt.legend(loc=10); # 0 ~ 10 까지 각각 위치가 다르다.

9. 판다스 subplot
그래프 속성 지정¶
- title() :
- xlabel() :
- ylabel() :
- gri() : 격자 눈금
- text() : 글씨를 출력 (tooltip을 간단하게 하고자 할 때)
plt에서 그래프 속성 지정
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
plt.plot( np.random.randn(100));
plt.plot( np.random.randn(200).cumsum());

하나의 화면에 여러 개의 그래프 그려보기*
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(12,8)); # figure로 전체 그래프의 액자 같은 개념으로 액자 크기 조절이 가능하다
ax1 = fig.add_subplot(1,2,1); # 1행 2열에서 1번째
ax2 = fig.add_subplot(1,2,2); # 1행 2열에서 2번째
ax1.plot( np.random.randn(100));
ax2.plot( np.random.randn(200).cumsum());

x, y 축 값 범위 지정
fig = plt.figure()
ax = fig.add_subplot(111) # 1, 1, 1
ax.plot(np.random.randn(100), 'b*--');
ax.set_title('Sample');
ax.set_xlabel('data-x');
ax.set_ylabel('data-y');

x 축 간격
fig = plt.figure()
ax = fig.add_subplot(111)
ax.plot(np.random.randn(100), 'b*--');
ax.set_title('Sample');
ax.set_xlabel('data-x');
ax.set_ylabel('data-y');
ax.set_xticks([10,50,100,150]);

10. 판다스 subplot 방식
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
1. figure(그림틀=공간?)을 만들고 거기에 subplot을 추가 하는 방식
fig = plt.figure();
ax1 = fig.add_subplot(1,2,1);
ax2 = fig.add_subplot(1,2,2);
ax1.plot( np.random.randn(100));
ax2.plot( np.random.randn(200).cumsum());

2. figure로 공간을 만들고 파이플롯(pyplot)의 subplot()으로 각각의 패널 지정
fig = plt.figure();
ax1 = plt.subplot(1,2,1);
ax2 = plt.subplot(1,2,2);
ax1.plot( np.random.randn(100));
ax2.plot( np.random.randn(200).cumsum());

3. 간단하게 ax 객체를 이용하기
fig = plt.figure();
fig, ax = plt.subplots(1,2); # 1행 2열의 공간을 생성
ax[0].plot( np.random.randn(100));
ax[1].plot( np.random.randn(200).cumsum());
<Figure size 432x288 with 0 Axes>
4. 그래프 전체 크기를 지정
- 공간의 크기를 지정하려면 subplots() 안에 옵션으로 기술한다.
fig,ax = plt.subplots(1,2, figsize=(12,8));
ax[0].plot( np.random.randn(100));
ax[1].plot( np.random.randn(200).cumsum());

plt.figure(figsize=(12,8))
plt.subplot(2,2,1) # 2행 2열 첫 번째 영역
plt.subplot(2,2,2) # 2행 2열 두 번째 영역
plt.subplot(2,1,2) # 2행 1열 두 번째 영역
plt.show()

- Q. 연습 1
plt.figure(figsize=(12,8));
plt.subplot(2,1,1);
plt.subplot(2,2,3);
plt.subplot(2,2,4);

- Q. 연습 2
plt.figure(figsize=(12,8));
plt.subplot(2,3,(1,2));
plt.subplot(2,3,3);
plt.subplot(2,1,2);

- Q. 연습 3
11. 판다스 화살표와 주석
차트상에서 주석 처리하는 함수 : annotate(s, xy, xytext, arrowprops, . . . )¶
+ s: 주석
+ xy : 화살표시작위치
+ xytext : 주석 텍스트의 시작 위치
+ arrowprops : 화살표의 속성들
[참고]
Matplotlib에서 화살표를 그리는 것은 plt.arrow()가 있지만 사용하기 어렵다.
게다가 플롯의 사로 세로 비율이 바뀔 때마다 원하는 결과 얻기 어렵다.
plt.annotate() 함수 이용을 권장한다
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0, 20, 100);
fig, ax = plt.subplots();
ax.plot(x, np.cos(x));
ax.axis('equal')
ax.annotate("My comment", xy=(6.30, 1), xytext=(10,4), arrowprops=dict(facecolor='pink', shrink=0.05) );
ax.annotate("Important thing", xy=(6.30, -1), xytext=(2,-6), arrowprops=dict(facecolor='pink', shrink=0.05) );

12. 판다스 연습문제 - 서울시 십대 정신건강 데이터


# 여기에 코드
import pandas as pd
pd.read_excel('./data/seoul_teenager.xls')
| 기간 | 구분 | 스트레스 인지율 | 스트레스 인지율.1 | 스트레스 인지율.2 | 우울감 경험률 | 우울감 경험률.1 | 우울감 경험률.2 | 자살 생각률 | 자살 생각률.1 | 자살 생각률.2 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 기간 | 구분 | 전체 | 남학생 | 여학생 | 전체 | 남학생 | 여학생 | 전체 | 남학생 | 여학생 |
| 1 | 2018 | 구분 | 42.7 | 34.5 | 51.5 | 29.6 | 24.2 | 35.4 | 15.4 | 11.8 | 19.2 |

# 여기에 코드
import pandas as pd
pd.read_excel('./data/seoul_teenager.xls', header=1, usecols='C:K')
| 전체 | 남학생 | 여학생 | 전체.1 | 남학생.1 | 여학생.1 | 전체.2 | 남학생.2 | 여학생.2 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 42.7 | 34.5 | 51.5 | 29.6 | 24.2 | 35.4 | 15.4 | 11.8 | 19.2 |

# 컬럼이름을 지정
col_names = ['스트레스','스트레스남학생','스트레스여학생',
'우울감경험률','우울남학생','우울여학생',
'자살생각율','자살남학생','자살여학생']
# 변수에 저장하기(raw_data)
import pandas as pd
raw_data = pd.read_excel('./data/seoul_teenager.xls', header=1, usecols='C:K')
# 여기에 코드
raw_data.columns = col_names
raw_data
| 스트레스 | 스트레스남학생 | 스트레스여학생 | 우울감경험률 | 우울남학생 | 우울여학생 | 자살생각율 | 자살남학생 | 자살여학생 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 42.7 | 34.5 | 51.5 | 29.6 | 24.2 | 35.4 | 15.4 | 11.8 | 19.2 |
(2) 해당 데이타값의 반대값으로 행을 추가¶
예를 들어 스트레스를 받는다고 응답한 수가 42.7이면
아니라고 응답한 수가 100 - 42.7= 57.3 이다.
각 항목에 반대로 응답한 수의 값을 행으로 추가한다

# 반대의 데이타값을 가지는 행을 추가한다
# 여기에 코드
raw_data.loc[1] = 100 - (raw_data.loc[0])
raw_data
| 스트레스 | 스트레스남학생 | 스트레스여학생 | 우울감경험률 | 우울남학생 | 우울여학생 | 자살생각율 | 자살남학생 | 자살여학생 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 42.7 | 34.5 | 51.5 | 29.6 | 24.2 | 35.4 | 15.4 | 11.8 | 19.2 |
| 1 | 57.3 | 65.5 | 48.5 | 70.4 | 75.8 | 64.6 | 84.6 | 88.2 | 80.8 |

# 응답 컬럼으로 '그렇다'와 '아니다' 값을 추가
# 여기에 코드
raw_data['응답'] = ['그렇다', '아니다']
raw_data
| 스트레스 | 스트레스남학생 | 스트레스여학생 | 우울감경험률 | 우울남학생 | 우울여학생 | 자살생각율 | 자살남학생 | 자살여학생 | 응답 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 42.7 | 34.5 | 51.5 | 29.6 | 24.2 | 35.4 | 15.4 | 11.8 | 19.2 | 그렇다 |
| 1 | 57.3 | 65.5 | 48.5 | 70.4 | 75.8 | 64.6 | 84.6 | 88.2 | 80.8 | 아니다 |

# 여기에 코드
raw_data.reset_index()
raw_data.set_index('응답', inplace=True)
raw_data
| 스트레스 | 스트레스남학생 | 스트레스여학생 | 우울감경험률 | 우울남학생 | 우울여학생 | 자살생각율 | 자살남학생 | 자살여학생 | |
|---|---|---|---|---|---|---|---|---|---|
| 응답 | |||||||||
| 그렇다 | 42.7 | 34.5 | 51.5 | 29.6 | 24.2 | 35.4 | 15.4 | 11.8 | 19.2 |
| 아니다 | 57.3 | 65.5 | 48.5 | 70.4 | 75.8 | 64.6 | 84.6 | 88.2 | 80.8 |

%matplotlib inline
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
# 폰트를 변경하면 '-' 기호가 네모로 변경되기에 '-'기호를 변경하지 않도록 설정
plt.rcParams['axes.unicode_minus'] = False
f_path = 'c:/Windows/Fonts/malgun.ttf'
font_name = font_manager.FontProperties(fname=f_path).get_name()
rc('font', family=font_name)
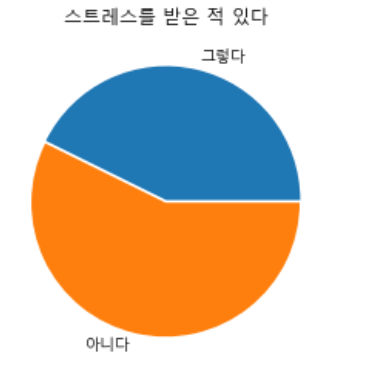
# 여기에 코드
stress = raw_data['스트레스']
splot = stress.plot.pie( explode=(0,0.02));
splot.set_title('스트레스를 받은 적 있다');
splot.set_ylabel('');

plt.figure(figsize=(16,5));
ax1 = plt.subplot(1,3,1);
ax2 = plt.subplot(1,3,2);
ax3 = plt.subplot(1,3,3);
stress = raw_data['스트레스']
depress = raw_data['우울감경험률']
suicide = raw_data['자살생각율']
ax1.pie(stress, labels=raw_data.index, autopct='%1.1f%%', explode=(0,0.02) );
ax1.set_title('스트레스를 받은 적 있다');
ax2.pie(depress, labels=raw_data.index, autopct='%1.1f%%', explode=(0,0.02) );
ax2.set_title('우울증을 경험한 적 있다');
ax3.pie(suicide, labels=raw_data.index, autopct='%1.1f%%', explode=(0,0.02) );
ax3.set_title('자살을 생각한 적 있다');
center_circle = plt.Circle((0,0), 0.70, color='black', fc='white', linewidth=0);
ax2.add_artist(center_circle);

13. 판다스 평가
# 1
import pandas as pd
inchun_subway = pd.read_csv('./data/inchun_subway.csv')
inchun_subway
| 역명 | 월 | 이용인원 | 승차인원 | 하차인원 | |
|---|---|---|---|---|---|
| 0 | 계양 | 1 | 193593 | 95967 | 97626 |
| 1 | 귤현 | 1 | 56611 | 26409 | 30202 |
| 2 | 박촌 | 1 | 239187 | 124728 | 114459 |
| 3 | 임학 | 1 | 487274 | 248486 | 238788 |
| 4 | 계산 | 1 | 694152 | 349866 | 344286 |
| ... | ... | ... | ... | ... | ... |
| 343 | 테크노파크 | 12 | 180521 | 90714 | 89807 |
| 344 | 지식정보단지 | 12 | 228977 | 114444 | 114533 |
| 345 | 인천대입구 | 12 | 240576 | 120417 | 120159 |
| 346 | 센트럴파크 | 12 | 126305 | 62740 | 63565 |
| 347 | 국제업무지구 | 12 | 30359 | 15091 | 15268 |
348 rows × 5 columns
# 2
inchun_subway.loc[:, '역명':'이용인원']
| 역명 | 월 | 이용인원 | |
|---|---|---|---|
| 0 | 계양 | 1 | 193593 |
| 1 | 귤현 | 1 | 56611 |
| 2 | 박촌 | 1 | 239187 |
| 3 | 임학 | 1 | 487274 |
| 4 | 계산 | 1 | 694152 |
| ... | ... | ... | ... |
| 343 | 테크노파크 | 12 | 180521 |
| 344 | 지식정보단지 | 12 | 228977 |
| 345 | 인천대입구 | 12 | 240576 |
| 346 | 센트럴파크 | 12 | 126305 |
| 347 | 국제업무지구 | 12 | 30359 |
348 rows × 3 columns
# 3
summary_sub = inchun_subway.loc[:, '역명':'이용인원']
summary_sub[summary_sub['역명'].str.contains(r'^인천대입구$')]
| 역명 | 월 | 이용인원 | |
|---|---|---|---|
| 26 | 인천대입구 | 1 | 109605 |
| 55 | 인천대입구 | 2 | 110610 |
| 84 | 인천대입구 | 3 | 301332 |
| 113 | 인천대입구 | 4 | 307075 |
| 142 | 인천대입구 | 5 | 297375 |
| 171 | 인천대입구 | 6 | 228245 |
| 200 | 인천대입구 | 7 | 154568 |
| 229 | 인천대입구 | 8 | 123748 |
| 258 | 인천대입구 | 9 | 288417 |
| 287 | 인천대입구 | 10 | 320416 |
| 316 | 인천대입구 | 11 | 300342 |
| 345 | 인천대입구 | 12 | 240576 |
# 4
summary_sub = inchun_subway.loc[:, '역명':'이용인원']
destination_sub = summary_sub[ summary_sub['역명'].str.contains(r'\국제업무지구') |
summary_sub['역명'].str.contains(r'\테크노파크') |
summary_sub['역명'].str.contains(r'\박촌')]
destination_sub.iloc[:10]
| 역명 | 월 | 이용인원 | |
|---|---|---|---|
| 2 | 박촌 | 1 | 239187 |
| 24 | 테크노파크 | 1 | 136796 |
| 28 | 국제업무지구 | 1 | 19402 |
| 31 | 박촌 | 2 | 225404 |
| 53 | 테크노파크 | 2 | 135851 |
| 57 | 국제업무지구 | 2 | 19061 |
| 60 | 박촌 | 3 | 272128 |
| 82 | 테크노파크 | 3 | 158498 |
| 86 | 국제업무지구 | 3 | 28830 |
| 89 | 박촌 | 4 | 276003 |
# 5
inchun_subway[['승차인원', '하차인원']].mean()
승차인원 209927.060345
하차인원 207138.663793
dtype: float64# 6
summary_sub = inchun_subway.loc[:, '역명':'이용인원']
unique_sub = summary_sub.drop_duplicates('역명', keep='first', inplace=False)['역명']
import numpy as np
np.sort(np.array(unique_sub))
array(['간석오거리', '갈산', '경인교대입구', '계산', '계양', '국제업무지구', '귤현', '동막', '동수',
'동춘', '문학경기장', '박촌', '부평', '부평구청', '부평삼거리', '부평시장', '선학', '센트럴파크',
'신연수', '예술회관', '원인재', '인천대입구', '인천시청', '인천터미널', '임학', '작전',
'지식정보단지', '캠퍼스타운', '테크노파크'], dtype=object)# 7
summary_sub = inchun_subway.loc[:, '역명':'이용인원']
summary_sub.groupby('역명').sum('이용인원')
passenger_sub = pd.DataFrame(summary_sub.groupby('역명').sum('이용인원')).reset_index()
passenger_sub[['역명','이용인원']]
| 역명 | 이용인원 | |
|---|---|---|
| 0 | 간석오거리 | 9608477 |
| 1 | 갈산 | 6919100 |
| 2 | 경인교대입구 | 5545464 |
| 3 | 계산 | 9448304 |
| 4 | 계양 | 2787752 |
| 5 | 국제업무지구 | 408363 |
| 6 | 귤현 | 810665 |
| 7 | 동막 | 4468472 |
| 8 | 동수 | 3075778 |
| 9 | 동춘 | 7635479 |
| 10 | 문학경기장 | 1616661 |
| 11 | 박촌 | 3076220 |
| 12 | 부평 | 5341429 |
| 13 | 부평구청 | 5350634 |
| 14 | 부평삼거리 | 1939777 |
| 15 | 부평시장 | 8441009 |
| 16 | 선학 | 5301806 |
| 17 | 센트럴파크 | 1511807 |
| 18 | 신연수 | 4479163 |
| 19 | 예술회관 | 8518929 |
| 20 | 원인재 | 2726860 |
| 21 | 인천대입구 | 2782309 |
| 22 | 인천시청 | 5052240 |
| 23 | 인천터미널 | 13107608 |
| 24 | 임학 | 6106961 |
| 25 | 작전 | 11276776 |
| 26 | 지식정보단지 | 2591975 |
| 27 | 캠퍼스타운 | 3193791 |
| 28 | 테크노파크 | 2015063 |
# 8
summary_sub = inchun_subway.loc[:, '역명':'이용인원']
passenger_sub = summary_sub.groupby('역명').sum('이용인원')
from pandas import Series
from matplotlib import font_manager, rc
plt.rcParams['axes.unicode_minus']=False
rc('font', family='Malgun Gothic')
import matplotlib.pyplot as plt
plt.figure(figsize=(9,7));
splot = passenger_sub['이용인원'].plot.barh(color='orange');
splot.set_xlabel('이용인원');
splot.invert_yaxis()
splot.set_ylabel('');
