2021. 2. 11. 11:56ㆍ교육과정/KOSMO
키워드 : 회귀분석 / 회귀분석을 이용한 날씨 예측 / 로지스틱 회귀분석을 이용한 생존자 예측 / 최적의 알고리즘 찾기(아이리스 데이터셋) / 사이킷런 KNN 분류모델 / 사이킷런 SVM 분류모델 / 비만지수 데이터셋
****
1. 회귀분석 - 전기사용량과 전기요금의 상관관계 / 온도와 오존의 상관관계 / 범죄율과 주택가격의 상관관계
회귀분석 (Regression)¶
- 독립변수(X)와 종속변수(Y)의 관계식에서 독립변수가 한 단위 증가할 때 종속변수가 얼마나 영향을 받는지 분석
[예] 연속형변수와 연속형 변수를 비교할 때
- 나이(X)가 많을 수록 소득(Y)가 높은지 분석
- 광고지불비(X)에 따라 판매량이 영향을 받는지 분석
- 가계 수입과 사교육비 지출 사이에 관계가 있는지 분석
- 신종코로나 추이 분석 (https://news.v.daum.net/v/20200213050105962)
[참고]


** 회귀분석 종류
1) 단순회귀 분석 : 독립변수가 1개
` 광고지불비(X)를 이용하여 상품 매출액(Y) 예측할 때
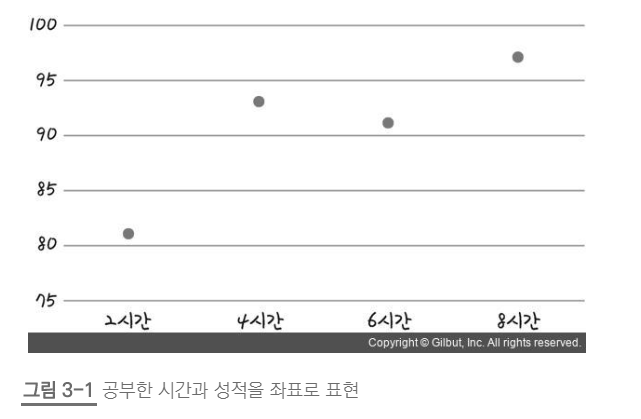
2) 다중회귀 분석 : 독립변수가 2개 이상
` 어린이 연령(X1)과 하루 평균 학습시간(X2)를 이용하여 그 어린이의 성적(Y)을 예측하고자 할 때%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import statsmodels.api as sm
from scipy import stats
from matplotlib import font_manager, rc
from statsmodels.sandbox.regression.predstd import wls_prediction_std
from sklearn.datasets import make_regression
# 한글 폰트 설정
font_name = font_manager.FontProperties(fname="c:/Windows/Fonts/malgun.ttf").get_name()
rc('font', family=font_name)
단순회귀분석 ( 선형회귀분석 )¶
-
독립변수가 1개인 경우
-
전기생산량(독립변수)과 전기소비량(종속변수)의 영향
- 귀무가설 : 전기생산량과 전기소비량 간에 상관관계가 없다
- 대립가설 : 전기생산량과 전기소비량 간에 상관관계가 있다# 월별 전기생산금액
x= [3.52, 2.51, 3.91, 4.07, 3.98, 4.29, 4.81, 3.73, 4.61, 3.39, 3.20]
# 월별 전기 사용량
y= [2.48, 2.27, 2.47, 2.37, 3.09, 3.18, 3.88, 3.03, 3.55, 2.99, 2.88]
##### 단순회귀분석
result = stats.linregress(x, y)
result
LinregressResult(slope=0.5546831443969521, intercept=0.8074740247672794, rvalue=0.7200942961345399, pvalue=0.012451312531534768, stderr=0.17816251936092412)- 기울기(slope)
- 절편(intercept)
- 상관계수(rvalue) :상관관계의 정도를 파악하는 값 ( -1에서 1 )
- 1에 근접하면 양의 상관관계 - -1에 근접하면 음의 상관관계 - 0에 근접하면 상관관계가 없다 - pvalue : 예측 불확실성의 정도를 나타내는 값 ( 0.05보다 크면 귀무가설을 채택할 수 있다. )
- 에러의 표준편차(stderr)
- 상관분석 : 두 변수 간에 선형적 관계가 있는지 분석
- 상관계수 : 상관관계의 정도를 파악하는 값 ( -1에서 1 )
- 1에 근접하면 양의 상관관계 - -1에 근접하면 음의 상관관계 - 0에 근접하면 상관관계가 없다
1) pvalue가 0.05보다 작으므로 통계적으로 유의미하기에 귀무가설을 기각하고 대립가설을 채택하여 전기생랸량과 소비생산량 간에 상관관계가 있다
2) rvalue(상관계수)가 1에 가까우므로 양의 상관관계가 있다고 볼 수 있다
##### 선형 회귀 분석값 얻어오기
slope, intercept, r_value, p_value, stderr = stats.linregress(x, y)
print('기울기 : ', slope)
print('절편 : ', intercept)
print('설명력 : ', r_value)
print('p_value : ', p_value)
if p_value < 0.05:
print('유의미한 데이터')
else:
print('유의미하지 않은 데이터')
##### 산점도 그리기
plt.scatter(x, y);
##### 회귀선 그리기
# x좌표는 리스트형이어야 한다.
x1 = np.array(x)
plt.plot(x1, x1*slope + intercept, c='red') # (x, y, 옵션)(y = ax + b)
plt.xlabel('전기생산량');
plt.ylabel('전기사용량');
기울기 : 0.5546831443969521
절편 : 0.8074740247672794
설명력 : 0.7200942961345399
p_value : 0.012451312531534768
유의미한 데이터

# 전기생산량이 4인 경우
4*slope + intercept
3.0262066023550878# 전기생산량이 6인 경우
6*slope + intercept
4.135572891148993df = pd.read_csv('../data/ozone/ozone.csv')
df.head()
df.tail()
| Ozone | Solar.R | Wind | Temp | Month | Day | |
|---|---|---|---|---|---|---|
| 148 | 30.0 | 193.0 | 6.9 | 70 | 9 | 26 |
| 149 | NaN | 145.0 | 13.2 | 77 | 9 | 27 |
| 150 | 14.0 | 191.0 | 14.3 | 75 | 9 | 28 |
| 151 | 18.0 | 131.0 | 8.0 | 76 | 9 | 29 |
| 152 | 20.0 | 223.0 | 11.5 | 68 | 9 | 30 |
[ 작업단계 ]
-
결측치 행 제거
-
온도(Temp) 데이타 X와 오존(Ozone) 데이타 Y를 추출
-
회귀분석 결과 출력
[ 회귀 분석의 결과에 대한 분석 ]
# 결측치 제거 전 행 수
df.shape
(153, 6)# 결측치 행 제거
df2 = df.dropna()
df2.shape
(111, 6)# 회귀분석 값 확인
result = stats.linregress(df2['Temp'], df2['Ozone'])
result
LinregressResult(slope=2.439109905529362, intercept=-147.64607238059494, rvalue=0.6985414096486389, pvalue=1.552677229392932e-17, stderr=0.23931937849409174)- 귀무가설 : 온도가 오존에 영향을 미치지 않는다.
- 대립가설 : 온도가 오존에 영향을 미친다.
p_value : 1.5 * 10^(-17) < 0.05 : 대립가설 채택
rvalue : 0.7 즉 70%의 설명력을 갖는다.
[ 작업단계 ]
- 산점도와 회귀선 그리기
slope, intercept, r_value, p_value, stderr = stats.linregress(df2['Temp'], df2['Ozone'])
print('기울기 : ', slope)
print('절편 : ', intercept)
print('설명력 : ', r_value)
print('p_value : ', p_value)
if p_value < 0.05:
print('유의미한 데이터')
else:
print('유의미하지 않은 데이터')
##### 산점도 그리기
plt.scatter(df2['Temp'], df2['Ozone']);
##### 회귀선 그리기
# x좌표는 리스트형이어야 한다.
x1 = np.array(df2['Temp'])
plt.plot(x1, x1*slope + intercept, c='red') # (x, y, 옵션)(y = ax + b)
plt.xlabel('온도');
plt.ylabel('오존량');
기울기 : 2.439109905529362
절편 : -147.64607238059494
설명력 : 0.6985414096486389
p_value : 1.552677229392932e-17
유의미한 데이터

# 온도가 화씨 70도라면 오존량이 얼마일까? 예측
70*slope + intercept
23.0916210064604# pip install mglearn
import mglearn
# 보스턴 주택가격 데이터셋
from sklearn.datasets import load_boston
# 회귀분석을 위한 패키기
from sklearn.linear_model import LinearRegression
# 학습용, 검증용 데이터를 나누기 위한 패키기
from sklearn.model_selection import train_test_split
boston = load_boston()
boston
print(boston.DESCR)
- CRIM 인구 1인당 범죄 수
- ZN 25000평방 피트 이상의 주거 구역 비중
- INDUS 소매업 외 상업이 차지하는 면접 비율
- CHAS 찰스강 위치 변수 (1: 강주변, 0:이외 )
- NOX 일산화질소 농도 (parts per 10 million)
- RM 집의 평균 방수
- AGE 1940년 이전에 지어진 비율
- DIS 5가지 보스턴 시 고용 시설까지의 거리
- RAD 순환고속도로의 접근 용이성
TAX $10000 달러당 부동산 세율 총계
PTRATIO 지역별 학생과 교사 비율
- B 지역별 흑인 비율
- LSTAT 급여가 낮은 직업에 종사하는 인구 비율(%)
- MEDV 가격단위($1000)
# 데이터를 다루기 쉽도록 DataFrame으로 변환
df = pd.DataFrame(boston.data)
df
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00632 | 18.0 | 2.31 | 0.0 | 0.538 | 6.575 | 65.2 | 4.0900 | 1.0 | 296.0 | 15.3 | 396.90 | 4.98 |
| 1 | 0.02731 | 0.0 | 7.07 | 0.0 | 0.469 | 6.421 | 78.9 | 4.9671 | 2.0 | 242.0 | 17.8 | 396.90 | 9.14 |
| 2 | 0.02729 | 0.0 | 7.07 | 0.0 | 0.469 | 7.185 | 61.1 | 4.9671 | 2.0 | 242.0 | 17.8 | 392.83 | 4.03 |
| 3 | 0.03237 | 0.0 | 2.18 | 0.0 | 0.458 | 6.998 | 45.8 | 6.0622 | 3.0 | 222.0 | 18.7 | 394.63 | 2.94 |
| 4 | 0.06905 | 0.0 | 2.18 | 0.0 | 0.458 | 7.147 | 54.2 | 6.0622 | 3.0 | 222.0 | 18.7 | 396.90 | 5.33 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 501 | 0.06263 | 0.0 | 11.93 | 0.0 | 0.573 | 6.593 | 69.1 | 2.4786 | 1.0 | 273.0 | 21.0 | 391.99 | 9.67 |
| 502 | 0.04527 | 0.0 | 11.93 | 0.0 | 0.573 | 6.120 | 76.7 | 2.2875 | 1.0 | 273.0 | 21.0 | 396.90 | 9.08 |
| 503 | 0.06076 | 0.0 | 11.93 | 0.0 | 0.573 | 6.976 | 91.0 | 2.1675 | 1.0 | 273.0 | 21.0 | 396.90 | 5.64 |
| 504 | 0.10959 | 0.0 | 11.93 | 0.0 | 0.573 | 6.794 | 89.3 | 2.3889 | 1.0 | 273.0 | 21.0 | 393.45 | 6.48 |
| 505 | 0.04741 | 0.0 | 11.93 | 0.0 | 0.573 | 6.030 | 80.8 | 2.5050 | 1.0 | 273.0 | 21.0 | 396.90 | 7.88 |
506 rows × 13 columns
# 컬럼명 지정
df.columns = boston.feature_names
df
| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | B | LSTAT | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00632 | 18.0 | 2.31 | 0.0 | 0.538 | 6.575 | 65.2 | 4.0900 | 1.0 | 296.0 | 15.3 | 396.90 | 4.98 |
| 1 | 0.02731 | 0.0 | 7.07 | 0.0 | 0.469 | 6.421 | 78.9 | 4.9671 | 2.0 | 242.0 | 17.8 | 396.90 | 9.14 |
| 2 | 0.02729 | 0.0 | 7.07 | 0.0 | 0.469 | 7.185 | 61.1 | 4.9671 | 2.0 | 242.0 | 17.8 | 392.83 | 4.03 |
| 3 | 0.03237 | 0.0 | 2.18 | 0.0 | 0.458 | 6.998 | 45.8 | 6.0622 | 3.0 | 222.0 | 18.7 | 394.63 | 2.94 |
| 4 | 0.06905 | 0.0 | 2.18 | 0.0 | 0.458 | 7.147 | 54.2 | 6.0622 | 3.0 | 222.0 | 18.7 | 396.90 | 5.33 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 501 | 0.06263 | 0.0 | 11.93 | 0.0 | 0.573 | 6.593 | 69.1 | 2.4786 | 1.0 | 273.0 | 21.0 | 391.99 | 9.67 |
| 502 | 0.04527 | 0.0 | 11.93 | 0.0 | 0.573 | 6.120 | 76.7 | 2.2875 | 1.0 | 273.0 | 21.0 | 396.90 | 9.08 |
| 503 | 0.06076 | 0.0 | 11.93 | 0.0 | 0.573 | 6.976 | 91.0 | 2.1675 | 1.0 | 273.0 | 21.0 | 396.90 | 5.64 |
| 504 | 0.10959 | 0.0 | 11.93 | 0.0 | 0.573 | 6.794 | 89.3 | 2.3889 | 1.0 | 273.0 | 21.0 | 393.45 | 6.48 |
| 505 | 0.04741 | 0.0 | 11.93 | 0.0 | 0.573 | 6.030 | 80.8 | 2.5050 | 1.0 | 273.0 | 21.0 | 396.90 | 7.88 |
506 rows × 13 columns
# 데이터(x)와 레이블(y) 지정
# 입력데이터와 답을 동시에 주고 규칙 찾기
x = df # 입력 데이터 : 13개의 특성
y = boston.target # 답 : 주택가격
# 데이터셋에서 훈련데이터셋과 검증(테스트)테이터셋을 분리
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=0)
x_train.head()
x_test.head()
print(x_train.shape)
print(x_test.shape)
(354, 13)
(152, 13)
# 모델에 학습하기
lr = LinearRegression().fit(x_train, y_train) # 학습 데이터와 학습라벨
# 검증하기
result_train = lr.score(x_train, y_train)
result_test = lr.score(x_test, y_test)
print('훈련 데이터 점수 : {:2f}'.format(result_train))
print('검증 데이터 점수 : {:2f}'.format(result_test))
훈련 데이터 점수 : 0.764545
검증 데이터 점수 : 0.673383
# 1번 데이터 확인
x.head(1)
| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | B | LSTAT | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00632 | 18.0 | 2.31 | 0.0 | 0.538 | 6.575 | 65.2 | 4.09 | 1.0 | 296.0 | 15.3 | 396.9 | 4.98 |
# 1번 데이터 라벨 확인
y[0]
2. 회귀분석 - 기온데이터를 이용한 날씨 예측
1. 기상청 데이타 준비¶
-
https://data.kma.go.kr > 데이터 > 기상관측 > 지상 > 종관기상관측(ASOS)
- 자료형태 : 일 자료
- 날짜 : 10년 데이타 : 2010 01 01 ~ 2019 12 31
- 지점 : 서울
- 기온 : 평균 기온
- weather 폴더 안에 'raw.csv' 파일로 저장
2. 데이타 정리¶
- raw.csv 파일을 읽어서 아래와 같이 가공하여 data.csv 파일로 저장
연,월,일,기온,품질,균질
2006,1,1,3.6,8,1
2006,1,2,4,8,1
2006,1,3,3.7,8,1
2006,1,4,4,8,1
2006,1,5,3.6,8,1
2006,1,6,2.1,8,1
....
[주의]
기존에 생성된 csv 파일이 EUC-KR인 경우가 많기에 문자셋 지정한다.
그러나 저장하는 data.csv 파일은 UTF-8로 문자셋을 지정하여 저장한다.in_file = "../data/weather/raw.csv"
out_file = "../data/weather/data.csv"
# CSV 파일을 한 줄 씩 읽어 들이기 ---(*1)
with open(in_file, "rt", encoding="EUC_KR") as fr:
lines = fr.readlines()
print(type(lines))
print(lines[:5])
# 기존의 데이터를 분리해서 가공하기 ---(*2)
# - 기존 데이타에서 5줄을 버리고 앞에 ["연,월,일,기온,품질,균질\n"] 붙이고자
lines = ["연,월,일,기온,품질,균질\n"] + lines[5:]
print(lines[:2])
# - /를 , 으로 변경
# map( function, list ) : list 각각의 요소에 함수를 적용
lines = map(lambda v: v.replace('/', ','), lines)
print(type(lines)) # : 여기서 lines은 map 객체임
# "".join(lines) : map 객체를 str 형태로
# strip()은 문자열을 처음과 끝에있는 공백문자를 제거
result = "".join(lines).strip()
# print(result)
# 결과를 파일에 출력하기 ---(*3)
with open(out_file, "wt", encoding="utf-8") as fw:
fw.write(result)
print("saved.")
<class 'list'>
['저장한 날짜: 2017/10/24 11:09:57,,,\n', ',,,\n', ',서울,서울,서울\n', '연월일,평균기온,평균기온,평균기온\n', ',,품질정보,균질정보\n']
['연,월,일,기온,품질,균질\n', '2006/1/1,3.6,8,1\n']
<class 'map'>
saved.
3. 학습 데이타와 테스트 데이타 만들기¶
- 예를 들어 2010년부터 2019년 데이타까지 있다면
2006년~2015년 데이타는 학습데이타로
2016년 데이타는 테스트데이타로
-
과거 6일의 데이터를 기반으로 학습할 데이터 만들기
예를 들어 현재 7일이라면 앞에 1일부터 6일까지는 학습데이타(X)가 되고 7일 데이타는 라벨(Y)가 된다.
from sklearn.linear_model import LinearRegression
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 기온 데이터 읽어 들이기
df = pd.read_csv('../data/weather/data.csv', encoding="utf-8")
# 데이터를 학습 전용과 테스트 전용으로 분리하기
train_year = (df["연"] <= 2015)
test_year = (df["연"] >= 2016)
interval = 6
# 과거 6년의 데이터를 기반으로 학습할 데이터 만들기
def make_data(data):
x = [] # 학습 데이터
y = [] # 결과
temps = list(data["기온"])
# 어렵게 구현했네
for i in range(len(temps)):
if i < interval: continue
y.append(temps[i])
xa = []
for p in range(interval):
d = i + p - interval
xa.append(temps[d])
x.append(xa)
return (x, y)
train_x, train_y = make_data(df[train_year])
test_x, test_y = make_data(df[test_year])
4. 선형 회귀 분석하기 ( LinearRegression )을 이용하여 예측하기¶
학습 후 예측값 (pre_y) 지정
# 모델에 학습하기
lr = LinearRegression().fit(train_x, train_y)
# 예측값
pre_y = lr.predict(test_x) # 결과로 나온 pre_y와 윗 단계에서 구한 test_y를 비교
# 검증하기
result_train = lr.score(train_x, train_y)
result_test = lr.score(test_x, test_y)
print('훈련 데이터 점수 : {:2f}'.format(result_train))
print('검증 데이터 점수 : {:2f}'.format(result_test))
훈련 데이터 점수 : 0.940718
검증 데이터 점수 : 0.923476
5. 결과를 그래프로 그리기¶
결과(test_y)와 예측(pre_y)을 그래프로 표현하기
plt.figure(figsize=(12,7));
plt.plot(test_y, c='red');
plt.plot(pre_y, c='blue');

6. 결과 평가하기¶
예측 기온과 실제 기온의 차이를 구해서 확인
pre_y - test_y
예측과 실제 차이의 평균과 최대 오차값을 구해서 확인한다
아래 결과를 확인하면 예측과 실제 차이의 평균은 1.66도 정도이고 최대 오차값은 8.47 정도이다
# import mean, max from numpy
diff_y = abs(pre_y - test_y)
print('평균 차이 : ', diff_y.mean())
print('최고 차이 : ', max(diff_y))
평균 차이 : 1.664068497195426
최고 차이 : 8.471949619908472
[참고도서] 파이썬을 이용한 머신러닝, 딥러닝 실전 앱 개발 (위키북스)
3. 로지스틱 회귀분석 - 타이타닉 생존자 예측
로지스틱 회귀분석¶
-
Logistic Regression 기본 배경
-
참/거짓으로 분류
-
이분으로 분류 : 합격인가 불합격인가
-
로지스틱 회귀 분석은 연속적인 값을 가지더라고, 로지스틱 함수의 결과값은 0과 1 사이의 값을 갖기에 이분법적인 분류 문제 해결하는 모형으로 적합하다
-
- LOGIT 적용분야
- 기업 부도 예측
- 주가-환율-금리 예측
[참고] 로지스틱 회귀


[참고] 시그모이드 함수
[참고] 로지스틱회귀에서 퍼셉트론으로


[그림] 모두의 딥러딩
이 퍼셉트론은 그 후 인공신경망, 오차역전파 등의 발전을 거쳐 딥러닝으로 이어지게 된다.
import pandas as pd
import numpy as np
import statsmodels.api as sm
타이타닉 데이타¶
성별(Sex), 나이(Age), 객실등급(Pclass), 요금(Fare)가 생존에 어느 정도의 영향을 미치는가
# 데이타 로딩
df = pd.read_csv('../data/titanic/temp/train.csv')
df.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
데이타처리
1) 나이, 요금은 숫자형으로 그래도 사용
2) 성별과 male/ female로 바로 처리할 수 없다
3) 객실등급은 1, 2, 3 으로 이루어져 있지만, 3등석이 높은 값으로 처리하여 결과가 외곡될 수 있다.# 바로 사용할 데이터의 컬럼들
cols_to_keep = ['Survived', 'Age', 'Fare']
# One-hot encoding 방식
dummy_Pclass = pd.get_dummies(df['Pclass'], prefix='Pclass')
dummy_Pclass.head()
dummy_Sex = pd.get_dummies(df['Sex'], prefix='Sex')
dummy_Sex.head()
| Sex_female | Sex_male | |
|---|---|---|
| 0 | 0 | 1 |
| 1 | 1 | 0 |
| 2 | 1 | 0 |
| 3 | 1 | 0 |
| 4 | 0 | 1 |
# 원본 데이터에서 필요한 데이터만 추출
data = df[cols_to_keep]
data.head()
# 더미데이터와 join하여 테이블 완성
data = data.join(dummy_Pclass)
data.head()
data = data.join(dummy_Sex)
data.head()
| Survived | Age | Fare | Pclass_1 | Pclass_2 | Pclass_3 | Sex_female | Sex_male | |
|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 22.0 | 7.2500 | 0 | 0 | 1 | 0 | 1 |
| 1 | 1 | 38.0 | 71.2833 | 1 | 0 | 0 | 1 | 0 |
| 2 | 1 | 26.0 | 7.9250 | 0 | 0 | 1 | 1 | 0 |
| 3 | 1 | 35.0 | 53.1000 | 1 | 0 | 0 | 1 | 0 |
| 4 | 0 | 35.0 | 8.0500 | 0 | 0 | 1 | 0 | 1 |
# 모델 선택
train_data = data.columns[1:]
train_label = data['Survived']
logit = sm.Logit(train_label, data[train_data])
# 학습하기
result = logit.fit()
Optimization terminated successfully.
Current function value: 0.451818
Iterations 7
# 결과 확인
result.summary()
| Dep. Variable: | Survived | No. Observations: | 891 |
|---|---|---|---|
| Model: | Logit | Df Residuals: | 885 |
| Method: | MLE | Df Model: | 5 |
| Date: | Wed, 10 Feb 2021 | Pseudo R-squ.: | 0.3215 |
| Time: | 22:58:13 | Log-Likelihood: | -402.57 |
| converged: | True | LL-Null: | -593.33 |
| Covariance Type: | nonrobust | LLR p-value: | 2.853e-80 |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Age | -0.0330 | 0.007 | -4.457 | 0.000 | -0.048 | -0.019 |
| Fare | 0.0007 | 0.002 | 0.340 | 0.734 | -0.003 | 0.005 |
| Pclass_1 | 1.5419 | 4.22e+06 | 3.65e-07 | 1.000 | -8.27e+06 | 8.27e+06 |
| Pclass_2 | 0.4610 | 4.22e+06 | 1.09e-07 | 1.000 | -8.27e+06 | 8.27e+06 |
| Pclass_3 | -0.7374 | 4.22e+06 | -1.75e-07 | 1.000 | -8.27e+06 | 8.27e+06 |
| Sex_female | 1.9352 | 4.22e+06 | 4.59e-07 | 1.000 | -8.27e+06 | 8.27e+06 |
| Sex_male | -0.6697 | 4.22e+06 | -1.59e-07 | 1.000 | -8.27e+06 | 8.27e+06 |
분석결과¶
-
coef(회귀계수)를 기준으로 생존 확인
-
coef 수가 클수록 비례하고 음의 값이면 반비례하는 것이다.
- 나이가 적을 수록 생존확률이 높다
- 요금이 높을 수록 생존확률이 높다
- 객실등급에 따라 1등급 > 2등급 > 3긍급 순으로 생존확률이 높다
- 여자가 남자보다 생존 확룔이 높다 ( Sex_male은 남성값이기에 음수는 여성이 생존확률이 높다는 것이다 )
- 객실등급과 성별이 생존에 많은 영향을 미쳤다
# 기존 전체 데이타로 예측하기
data['predict'] = result.predict(data[train_data])
data.head(20)
| Survived | Age | Fare | Pclass_1 | Pclass_2 | Pclass_3 | Sex_female | Sex_male | predict | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 22.0 | 7.2500 | 0 | 0 | 1 | 0 | 1 | 0.106363 |
| 1 | 1 | 38.0 | 71.2833 | 1 | 0 | 0 | 1 | 0 | 0.906625 |
| 2 | 1 | 26.0 | 7.9250 | 0 | 0 | 1 | 1 | 0 | 0.585365 |
| 3 | 1 | 35.0 | 53.1000 | 1 | 0 | 0 | 1 | 0 | 0.913663 |
| 4 | 0 | 35.0 | 8.0500 | 0 | 0 | 1 | 0 | 1 | 0.071945 |
| 5 | 0 | 30.0 | 8.4583 | 0 | 0 | 1 | 0 | 1 | 0.083802 |
| 6 | 0 | 54.0 | 51.8625 | 1 | 0 | 0 | 0 | 1 | 0.294415 |
| 7 | 0 | 2.0 | 21.0750 | 0 | 0 | 1 | 0 | 1 | 0.188760 |
| 8 | 1 | 27.0 | 11.1333 | 0 | 0 | 1 | 1 | 0 | 0.577886 |
| 9 | 1 | 14.0 | 30.0708 | 0 | 1 | 0 | 1 | 0 | 0.876030 |
| 10 | 1 | 4.0 | 16.7000 | 0 | 0 | 1 | 1 | 0 | 0.746046 |
| 11 | 1 | 58.0 | 26.5500 | 1 | 0 | 0 | 1 | 0 | 0.829303 |
| 12 | 0 | 20.0 | 8.0500 | 0 | 0 | 1 | 0 | 1 | 0.112863 |
| 13 | 0 | 39.0 | 31.2750 | 0 | 0 | 1 | 0 | 1 | 0.064603 |
| 14 | 0 | 14.0 | 7.8542 | 0 | 0 | 1 | 1 | 0 | 0.677232 |
| 15 | 1 | 55.0 | 16.0000 | 0 | 1 | 0 | 1 | 0 | 0.643667 |
| 16 | 0 | 2.0 | 29.1250 | 0 | 0 | 1 | 0 | 1 | 0.189641 |
| 17 | 1 | 30.0 | 13.0000 | 0 | 1 | 0 | 0 | 1 | 0.233240 |
| 18 | 0 | 31.0 | 18.0000 | 0 | 0 | 1 | 1 | 0 | 0.546591 |
| 19 | 1 | 30.0 | 7.2250 | 0 | 0 | 1 | 1 | 0 | 0.552862 |
Survived 와 prdeict를 비교한다.
-
Survived=1이면 생존이고 predict 0.5 이상의 값이면 생존으로 예측한 것이다.
-
Survived=0이면 사망이고 predict 0.5 미만의 값이면 사망으로 예측한 것이다.
-
결과 확인 중 잘못 예측한 것도 있다 ( 14번째 )
4. 아이리스 데이터셋에서의 최적의 알고리즘 찾기
최적의 알고리즘 찾기¶
- all_estimators() 메소드 이용하여 모든 알고리즘 추출
[참고도서] 파이썬을 이용한 머신러닝, 딥러닝 실전 앱 개발 (위키북스)import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.utils.testing import all_estimators
import warnings
warnings.filterwarnings('ignore')
# 붓꽃 데이터 읽어 들이기
iris_data = pd.read_csv("../data/iris/iris.csv", encoding="utf-8")
# 붓꽃 데이터를 레이블과 입력 데이터로 분리하기
y = iris_data.loc[:,"variety"]
x = iris_data.loc[:,["sepal.length","sepal.width","petal.length","petal.width"]]
# (0) 학습 전용과 테스트 전용 분리하기
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2, train_size = 0.8, shuffle = True)
# (1) classifier 알고리즘 모두 추출하기
allAlgorithms = all_estimators(type_filter="classifier")
for(name, algorithm) in allAlgorithms:
# (1) 알고리즘 종류 확인
# print(name)
# 현재 자료형이 안 맞아서 학습되지 않는 알고리즘들이기에 제외해야 한다 -> 추가로 코딩을 예쁘게
if name=='CheckingClassifier' or name=='ClassifierChain' \
or name=='MultiOutputClassifier' or name=='OneVsOneClassifier' \
or name=='OneVsRestClassifier' or name=='OutputCodeClassifier' \
or name=='VotingClassifier' or name=='StackingClassifier':
continue
#-----------------------------------------
# 에러가 발생하면 위에 print(name)으로 알고리즘을 확인 후 에러난 알고리즘이름을 위에 추가한다
# (2) 각 알고리즘 객체 생성하기
clf = algorithm()
# (3) 학습하고 평가하기
clf.fit(x_train, y_train)
y_pred = clf.predict(x_test)
print(name,"의 정답률 = " , accuracy_score(y_test, y_pred))
AdaBoostClassifier 의 정답률 = 0.9333333333333333
BaggingClassifier 의 정답률 = 0.9666666666666667
BernoulliNB 의 정답률 = 0.23333333333333334
CalibratedClassifierCV 의 정답률 = 0.7666666666666667
CategoricalNB 의 정답률 = 0.9333333333333333
ComplementNB 의 정답률 = 0.6
DecisionTreeClassifier 의 정답률 = 0.9333333333333333
DummyClassifier 의 정답률 = 0.5
ExtraTreeClassifier 의 정답률 = 0.8333333333333334
ExtraTreesClassifier 의 정답률 = 0.9333333333333333
GaussianNB 의 정답률 = 0.9333333333333333
GaussianProcessClassifier 의 정답률 = 0.9666666666666667
GradientBoostingClassifier 의 정답률 = 0.9333333333333333
HistGradientBoostingClassifier 의 정답률 = 0.9333333333333333
KNeighborsClassifier 의 정답률 = 0.9666666666666667
LabelPropagation 의 정답률 = 0.9333333333333333
LabelSpreading 의 정답률 = 0.9333333333333333
LinearDiscriminantAnalysis 의 정답률 = 1.0
LinearSVC 의 정답률 = 0.9
LogisticRegression 의 정답률 = 0.9666666666666667
LogisticRegressionCV 의 정답률 = 1.0
MLPClassifier 의 정답률 = 0.9
MultinomialNB 의 정답률 = 0.7
NearestCentroid 의 정답률 = 0.9666666666666667
NuSVC 의 정답률 = 1.0
PassiveAggressiveClassifier 의 정답률 = 0.7
Perceptron 의 정답률 = 0.8333333333333334
QuadraticDiscriminantAnalysis 의 정답률 = 1.0
RadiusNeighborsClassifier 의 정답률 = 1.0
RandomForestClassifier 의 정답률 = 0.9333333333333333
RidgeClassifier 의 정답률 = 0.7333333333333333
RidgeClassifierCV 의 정답률 = 0.7333333333333333
SGDClassifier 의 정답률 = 0.7333333333333333
SVC 의 정답률 = 1.0
[ 문제점 ]
각 알고리즘의 정답률을 비교했지만, 평가 횟수가 1회 밖에고 사용한 데이타도 한 가지 패턴이다.
여러 데이타 패턴으로 평가하는 방법이 교차 검증(corss-validation)이다
K-교차 검증 (cross-validataion)¶
- K개의 그룹으로 분할
- K-1개의 학습 데이타
- 남은 1개의 평가 데이타
- K번 반복
import pandas as pd
from sklearn.utils.testing import all_estimators
from sklearn.model_selection import KFold
import warnings
from sklearn.model_selection import cross_val_score
# 붓꽃 데이터 읽어 들이기
iris_data = pd.read_csv("../data/iris/iris.csv", encoding="utf-8")
# 붓꽃 데이터를 레이블과 입력 데이터로 분리하기
y = iris_data.loc[:,"variety"]
x = iris_data.loc[:,["sepal.length","sepal.width","petal.length","petal.width"]]
# classifier 알고리즘 모두 추출하기
warnings.filterwarnings('ignore')
allAlgorithms = all_estimators(type_filter="classifier")
# (1)
# K-분할 크로스 밸리데이션 전용 객체
# 데이타를 5그룹으로 분할하고 분할할 때 랜덤하게 섞는다
kfold_cv = KFold(n_splits=5, shuffle=True)
for(name, algorithm) in allAlgorithms:
# 현재 자료형이 안 맞아서 학습되지 않는 알고리즘들이기에 제외해야 한다 -> 추가로 코딩을 예쁘게
if name=='CheckingClassifier' or name=='ClassifierChain' \
or name=='MultiOutputClassifier' or name=='OneVsOneClassifier' \
or name=='OneVsRestClassifier' or name=='OutputCodeClassifier' \
or name=='VotingClassifier' or name=='StackingClassifier':
continue
# (2) 각 알고리즘 객체 생성하기
clf = algorithm()
# (3)
# score 메서드를 가진 클래스를 대상으로 하기
if hasattr(clf,"score"):
# (4) 크로스 밸리데이션
# cross_val_score (clf:알고리즘 객체, x:입력데이터, y:레이블데이터, cv:교차검증 적용 객체)
scores = cross_val_score(clf, x, y, cv=kfold_cv)
print(name,"의 정답률=")
print(scores)
AdaBoostClassifier 의 정답률=
[1. 0.93333333 0.93333333 0.96666667 1. ]
BaggingClassifier 의 정답률=
[0.93333333 0.96666667 0.93333333 0.96666667 0.96666667]
BernoulliNB 의 정답률=
[0.26666667 0.23333333 0.26666667 0.16666667 0.3 ]
CalibratedClassifierCV 의 정답률=
[1. 0.93333333 0.93333333 0.93333333 0.8 ]
CategoricalNB 의 정답률=
[0.93333333 0.9 0.9 1. 0.9 ]
ComplementNB 의 정답률=
[0.66666667 0.63333333 0.66666667 0.6 0.76666667]
DecisionTreeClassifier 의 정답률=
[0.93333333 0.96666667 0.9 0.96666667 0.96666667]
DummyClassifier 의 정답률=
[0.2 0.36666667 0.36666667 0.4 0.46666667]
ExtraTreeClassifier 의 정답률=
[1. 0.86666667 0.96666667 0.9 0.93333333]
ExtraTreesClassifier 의 정답률=
[0.93333333 0.96666667 0.93333333 0.96666667 0.93333333]
GaussianNB 의 정답률=
[0.93333333 0.9 1. 0.96666667 0.96666667]
GaussianProcessClassifier 의 정답률=
[0.96666667 0.96666667 1. 0.9 0.96666667]
GradientBoostingClassifier 의 정답률=
[0.96666667 0.86666667 0.93333333 0.96666667 1. ]
HistGradientBoostingClassifier 의 정답률=
[0.93333333 1. 0.9 0.9 0.93333333]
KNeighborsClassifier 의 정답률=
[0.96666667 1. 0.96666667 0.93333333 0.93333333]
LabelPropagation 의 정답률=
[0.93333333 0.96666667 0.96666667 0.96666667 0.96666667]
LabelSpreading 의 정답률=
[0.96666667 0.96666667 1. 0.9 0.96666667]
LinearDiscriminantAnalysis 의 정답률=
[1. 0.93333333 0.96666667 1. 1. ]
LinearSVC 의 정답률=
[0.93333333 1. 0.96666667 0.96666667 0.93333333]
LogisticRegression 의 정답률=
[0.9 1. 0.96666667 1. 0.96666667]
LogisticRegressionCV 의 정답률=
[1. 1. 1. 0.9 0.96666667]
MLPClassifier 의 정답률=
[1. 0.96666667 0.93333333 1. 1. ]
MultinomialNB 의 정답률=
[0.96666667 0.96666667 0.93333333 0.93333333 0.9 ]
NearestCentroid 의 정답률=
[0.96666667 0.86666667 0.86666667 0.96666667 0.96666667]
NuSVC 의 정답률=
[0.93333333 0.96666667 0.96666667 0.93333333 0.96666667]
PassiveAggressiveClassifier 의 정답률=
[0.86666667 0.86666667 0.73333333 0.73333333 0.9 ]
Perceptron 의 정답률=
[0.66666667 0.7 0.8 0.63333333 0.76666667]
QuadraticDiscriminantAnalysis 의 정답률=
[0.93333333 0.93333333 0.96666667 1. 1. ]
RadiusNeighborsClassifier 의 정답률=
[0.9 0.96666667 0.96666667 0.93333333 0.93333333]
RandomForestClassifier 의 정답률=
[0.9 1. 0.96666667 0.93333333 0.9 ]
RidgeClassifier 의 정답률=
[0.76666667 0.86666667 0.93333333 0.8 0.73333333]
RidgeClassifierCV 의 정답률=
[0.86666667 0.73333333 0.86666667 0.8 0.9 ]
SGDClassifier 의 정답률=
[0.8 0.73333333 0.73333333 0.9 0.53333333]
SVC 의 정답률=
[0.9 0.93333333 1. 0.96666667 0.96666667]import pandas as pd
from sklearn.utils.testing import all_estimators
from sklearn.model_selection import KFold
import warnings
from sklearn.model_selection import cross_val_score
# 붓꽃 데이터 읽어 들이기
iris_data = pd.read_csv("../data/iris/iris.csv", encoding="utf-8")
# 붓꽃 데이터를 레이블과 입력 데이터로 분리하기
y = iris_data.loc[:,"variety"]
x = iris_data.loc[:,["sepal.length","sepal.width","petal.length","petal.width"]]
# 학습 전용과 테스트 전용 분리하기
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2, train_size = 0.8, shuffle = True)
# 그리드 서치에서 사용할 매개 변수 --- (*1)
parameters = [
{"C": [1, 10, 100, 1000], "kernel":["linear"]},
{"C": [1, 10, 100, 1000], "kernel":["rbf"], "gamma":[0.001, 0.0001]},
{"C": [1, 10, 100, 1000], "kernel":["sigmoid"], "gamma": [0.001, 0.0001]}
]
# 그리드 서치 --- (*2)
from sklearn.svm import SVC
from sklearn.model_selection import GridSearchCV
kfold_cv = KFold(n_splits=5, shuffle=True)
clf = GridSearchCV( SVC(), parameters, cv=kfold_cv)
clf.fit(x_train, y_train)
print("최적의 매개 변수 = ", clf.best_estimator_)
# 최적의 매개 변수로 평가하기 --- (*3)
y_pred = clf.predict(x_test)
print("최종 정답률 = " , accuracy_score(y_test, y_pred))
최적의 매개 변수 = SVC(C=1, kernel='linear')
최종 정답률 = 0.9666666666666667
5. 아이리스 데이터셋 살펴보기 (분석X, 그래프O)
붓꽃 데이타¶
iris(붓꽃) 데이타셋 : 빅데이타, 머신러닝, 통계 등에서 많이 사용하는 데이타
Sepal Length 꽃받침의 길이 정보이다.
Sepal Width 꽃받침의 너비 정보이다.
Petal Length 꽃잎의 길이 정보이다.
Petal Width 꽃잎의 너비 정보이다.
Species 꽃의 종류 정보이다. ( setosa / versicolor / virginica)
붓꽃 데이타를 학습 데이타로 어느 모델에 넣었을 때 분꽃종류를 정확히 맞추면
그 모델은 성능이 좋은 분류(classfication) 모델이다.
또한 여기는 label에 해당하는 Species가 있기에 지도학습에 해당된다.
[참고] https://scikit-learn.org/stable/auto_examples/datasets/plot_iris_dataset.html
[용어] 데이타셋에서
샘플 = 한 행 데이타
특성 = 한 열 데이타import numpy as np
from sklearn import datasets
iris = datasets.load_iris()
# ------------ iris 데이타셋 살펴보기
# 위의 참고문헌을 보면 iris는 Bunch클래스 객체인데 이는 Dictionary와 비슷한 구조
# Dictionary는 기본적으로 key와 value로 구성된다
print(iris.keys())
print(iris['data'][:10]) # 붓꽃의 4가지 정보
print(iris['target']) # 붓꽃의 종류를 0,1,2로 표현
print(iris['target_names'][:10]) # 붓꽃의 종류
print(type(iris['data'])) # 'numpy.ndarray'
print(iris['data'].shape)
print(iris['target'].shape)
dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names', 'filename'])
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]
[5.4 3.9 1.7 0.4]
[4.6 3.4 1.4 0.3]
[5. 3.4 1.5 0.2]
[4.4 2.9 1.4 0.2]
[4.9 3.1 1.5 0.1]]
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
['setosa' 'versicolor' 'virginica']
<class 'numpy.ndarray'>
(150, 4)
(150,)
# [참고] 간단하게 seaborn에 데이타셋으로 가져와서 그래프로 보면 꽃의 데이타로 species 를 알 수 있다
import seaborn as sns
sns.set(style='ticks')
iris = sns.load_dataset('iris')
sns.pairplot(iris, hue='species')
<seaborn.axisgrid.PairGrid at 0x274a2f009e8>
[ 그래프 ] 산점도 그래프
-
데이터에서 한 특성(feature)을 x축에 놓고 다른 하나는 y축에 놓아 각 데이터 포인트를 하니의 점으로 나타내는 그래프이다
-
특성(feature)가 적다면 그래프를 보며 클래스(꽃의 품좀)이 잘 구분되는지 확인한다.
-
물론 산점도 그래프는 특성들 간의 관계를 나타내는 것이 아니기 때문에 중요한 성질을 표현하지 못 할 수도 있다
6. 사이킷런 라이브러리의 KNN 분류모델 - 아이리스 데이터셋

* 절차¶
(1) 데이타 읽어오기
(2) 데이터와 레이블 분리 변수 선언
(3) 훈련데이터와 테스트 데이터로 분리하기
(4) 모델로 학습하기
(5) 예측하기
(6) 검증하기
(7) 정확도 측정하기
# (1) 데이타 읽어오기
import numpy as np
from sklearn import datasets
iris = datasets.load_iris()
print(iris.DESCR)
.. _iris_dataset:
Iris plants dataset
--------------------
**Data Set Characteristics:**
:Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, predictive attributes and the class
:Attribute Information:
- sepal length in cm
- sepal width in cm
- petal length in cm
- petal width in cm
- class:
- Iris-Setosa
- Iris-Versicolour
- Iris-Virginica
:Summary Statistics:
============== ==== ==== ======= ===== ====================
Min Max Mean SD Class Correlation
============== ==== ==== ======= ===== ====================
sepal length: 4.3 7.9 5.84 0.83 0.7826
sepal width: 2.0 4.4 3.05 0.43 -0.4194
petal length: 1.0 6.9 3.76 1.76 0.9490 (high!)
petal width: 0.1 2.5 1.20 0.76 0.9565 (high!)
============== ==== ==== ======= ===== ====================
:Missing Attribute Values: None
:Class Distribution: 33.3% for each of 3 classes.
:Creator: R.A. Fisher
:Donor: Michael Marshall (MARSHALL%PLU@io.arc.nasa.gov)
:Date: July, 1988
The famous Iris database, first used by Sir R.A. Fisher. The dataset is taken
from Fisher's paper. Note that it's the same as in R, but not as in the UCI
Machine Learning Repository, which has two wrong data points.
This is perhaps the best known database to be found in the
pattern recognition literature. Fisher's paper is a classic in the field and
is referenced frequently to this day. (See Duda & Hart, for example.) The
data set contains 3 classes of 50 instances each, where each class refers to a
type of iris plant. One class is linearly separable from the other 2; the
latter are NOT linearly separable from each other.
.. topic:: References
- Fisher, R.A. "The use of multiple measurements in taxonomic problems"
Annual Eugenics, 7, Part II, 179-188 (1936); also in "Contributions to
Mathematical Statistics" (John Wiley, NY, 1950).
- Duda, R.O., & Hart, P.E. (1973) Pattern Classification and Scene Analysis.
(Q327.D83) John Wiley & Sons. ISBN 0-471-22361-1. See page 218.
- Dasarathy, B.V. (1980) "Nosing Around the Neighborhood: A New System
Structure and Classification Rule for Recognition in Partially Exposed
Environments". IEEE Transactions on Pattern Analysis and Machine
Intelligence, Vol. PAMI-2, No. 1, 67-71.
- Gates, G.W. (1972) "The Reduced Nearest Neighbor Rule". IEEE Transactions
on Information Theory, May 1972, 431-433.
- See also: 1988 MLC Proceedings, 54-64. Cheeseman et al"s AUTOCLASS II
conceptual clustering system finds 3 classes in the data.
- Many, many more ...
# (2) 데이터와 레이블 분리 변수 선언 ( 이미 데이터와 레이블이 정해짐 )
x = iris['data']
x[:10]
y = iris['target']
y[:10]
y[100:110]
array([2, 2, 2, 2, 2, 2, 2, 2, 2, 2])# (3) 훈련데이터와 테스트 데이터로 분리하기
from sklearn.model_selection import train_test_split
# test_size를 기본값으로 하면 3:1
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=0);
print(x_train.shape)
print(x_test.shape)
print(y_train.shape)
print(y_test.shape)
'''
print(X_train[:10])
print(X_test[:10])
print(y_train[:10])
print(y_test[:10])
'''
(112, 4)
(38, 4)
(112,)
(38,)
'\nprint(X_train[:10])\nprint(X_test[:10])\nprint(y_train[:10])\nprint(y_test[:10])\n'# (4) 모델에 데이터를 학습하기
# 훈련데이타와 훈련레이블를 인자로 넣어 학습한 결과 knn 객체를 리턴한다
# n_neighbors : 이웃갯수 지정
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=1)
knn.fit(x_train, y_train)
KNeighborsClassifier(n_neighbors=1)# (5) 새로운 샘플 데이타가 들어왔을 때 label 예측하기
# 너무 동떨어진 데이타 입력하면 결과 예측 성능이 낮기에 기존 샘플과 유사하게 만듬
newData = np.array([[5.1, 2.9, 1., 0.3]])
pred = knn.predict(newData)
print(pred) # [0]
print(iris['target_names'][0])
[0]
setosa
# (6) 검증하기
# 실제 레이블과 예측값의 정확도 확인
print(knn.score(x_test, y_test))
0.9736842105263158
# (7) 정확도 측정
# 원리
'''
a = np.array([1,2,3,4])
b = np.array([1,2,3,5])
print(a==b)
print(np.mean(a==b)) # True=1, False=0 의 평균
'''
# 함수
from sklearn import metrics
y_predict = knn.predict(x_test)
ac_score = metrics.accuracy_score(y_test, y_predict)
print(ac_score) # 97%의 검증에 의해서 ~~ 로 예측합니다.
0.9736842105263158
7. 사이킷런 라이브러리의 SVM 분류모델 - 서포트벡터머신
* sklearn 라이브러리에서 간단한 분류 모델¶
- SVM ( Support Vector Machine )¶
- svm(서포트벡터머신:분류, 회귀) 알고리즘 : 분류(SVC), 회귀(SVR)
- fit() : 학습기계에 데이터를 학습시키는 메소드 - predict() : 데이터를 넣고 예측하는 메소드 - metrics.accuracy_score() : 정확도 측정 (검증)

+ 사용알고리즘 SVC ( 분류 )¶
from sklearn import svm
model = svm.SVC()
* 매개변수
1) gamma
- 데이터포인트 사이의 거리는 가우시안 커널에 의해 계산되는데, 가우시안 커널의 폭을 제어하는 매개변수
- 하나의 훈련 샘들이 미치는 영향의 범위를 결정
- gamma값이 크면 모델이 더 복잡해진다
2) C
- 각 포인트의 중요도를 제한
+ 머신러닝 프로그램 절차¶
(1) 데이타 읽기
(2) 데이터와 레이블 분리 변수 선언 - 데이타와 타켓(레이블)
* 데이타 분리 (열)
(3) 학습데이타와 검증 데이타 분류 - train_test_split()
* 데이타 분리 (행)
(4) 알고리즘 적용하여 학습 - fit()
(5) 예측 - predict()
(6) 정확도 - accuracy_score()
(7) 검증하기 - score()import pandas as pd
from sklearn import datasets
from sklearn import svm, metrics
from sklearn.model_selection import train_test_split
# 1. 데이타로딩
iris = datasets.load_iris()
# 2. 데이터와 레이블 분리 변수 선언
X= iris.data
y= iris.target
# 3. 데이터셋 분리 ( 학습데이타:검증데이타 = 7:3 )
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
# 4. 알고리즘 데이터를 학습시키고 예측하기
model = svm.SVC()
model.fit(X_train, y_train)
# 5. 예측하기
pred = model.predict(X_test)
print(pred)
# 6. 정확도
print(model.score(X_test, y_test))
# 7. 검증하기
print(metrics.accuracy_score(y_test, pred))
[2 1 0 2 0 2 0 1 1 1 2 1 1 1 1 0 1 1 0 0 2 1 0 0 2 0 0 1 1 0 2 1 0 2 2 1 0
2 1 1 2 0 2 0 0]
0.9777777777777777
0.9777777777777777
from sklearn import svm, metrics
import random, re # re : 정규표현식
# 1. 붓꽃 데이터 읽어 들이기
csv = []
with open('../data/iris/iris.csv','r', encoding='utf-8') as fp:
# iris.csv 파일을 r(읽기모드)로 열다
for line in fp: # 한 줄씩 읽어오기
line = line.strip() # 줄바꿈 제거
cols = line.split(',')# 쉼표로 컬럼을 구분
# 문자열 데이터를 숫자(실수)로 변환하기
# 파이썬의 삼항연산자
# (값)=(True일 때의 값) if (조건) else (False일 때의 값)
fn = lambda n:float(n) if re.match(r'^[0-9\.]+$',n) else n
cols = list(map(fn, cols))
csv.append(cols)
# 추후에 pandas로 간편하게 데이타셋 읽어올 수 있음
# 헤더(컬럼명) 제거
del csv[0]
# 품종별로 데이타 순서로 있기에 학습데이타와 테스트데이타를 나누기 전에 섞는다
# 그래야 각각의 데이타에 품종별로 골로루 데이타가 들어가도록
random.shuffle(csv)
# 학습데이타와 테스트 데이터로 분리하기
total_len = len(csv)
train_len = int(total_len*2/3) # 학습데이타 2/3, 테스트데이터 1/3
train_data=[]
train_label=[]
test_data=[]
test_label=[]
for i in range(total_len):
data=csv[i][0:4]
label=csv[i][4]
if i < train_len:
train_data.append(data)
train_label.append(label)
else:
test_data.append(data)
test_label.append(label)
print(train_data[:10])
print(train_label[:10])
print(test_data[:10])
print(test_label[:10])
[[6.3, 3.4, 5.6, 2.4], [6.3, 2.8, 5.1, 1.5], [6.2, 2.9, 4.3, 1.3], [5.1, 3.5, 1.4, 0.3], [5.0, 3.5, 1.3, 0.3], [4.7, 3.2, 1.6, 0.2], [5.4, 3.4, 1.7, 0.2], [5.8, 2.7, 3.9, 1.2], [6.2, 2.2, 4.5, 1.5], [4.8, 3.1, 1.6, 0.2]]
['"Virginica"', '"Virginica"', '"Versicolor"', '"Setosa"', '"Setosa"', '"Setosa"', '"Setosa"', '"Versicolor"', '"Versicolor"', '"Setosa"']
[[6.9, 3.1, 5.1, 2.3], [6.0, 2.9, 4.5, 1.5], [4.8, 3.0, 1.4, 0.3], [7.7, 3.0, 6.1, 2.3], [4.7, 3.2, 1.3, 0.2], [6.0, 3.4, 4.5, 1.6], [5.5, 2.4, 3.7, 1.0], [7.4, 2.8, 6.1, 1.9], [5.6, 3.0, 4.1, 1.3], [5.8, 2.7, 5.1, 1.9]]
['"Virginica"', '"Versicolor"', '"Setosa"', '"Virginica"', '"Setosa"', '"Versicolor"', '"Versicolor"', '"Virginica"', '"Versicolor"', '"Virginica"']
# 분류모델을 이용하여 학습데이타를 넣고 훈련하고 예측한다
clf = svm.SVC(gamma='auto')
clf.fit(train_data, train_label) # 학습하기
pre_label = clf.predict(test_data) # 예측하기
# 검증하기 - 정확도
ac_score = metrics.accuracy_score(test_label, pre_label)
print(ac_score)
0.96
8. 비만지수 데이터셋을 이용한 분석 - SVM를 이용하여 산점도 그래프 그리기, 랜덤포레스트를 이용하여 그래프 그리기
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import statsmodels.api as sm
import seaborn as sns
from scipy import stats
from matplotlib import font_manager, rc
from statsmodels.sandbox.regression.predstd import wls_prediction_std
from sklearn.datasets import make_regression
# 한글 폰트 설정
font_name = font_manager.FontProperties(fname="c:/Windows/Fonts/malgun.ttf").get_name()
rc('font', family=font_name)
from sklearn import svm, metrics
from sklearn.model_selection import train_test_split
import pandas as pd
# 데이타 읽어오기
tbl = pd.read_csv('../data/bmi/bmi.csv')
tbl
| height | weight | label | |
|---|---|---|---|
| 0 | 194 | 68 | 저체중 |
| 1 | 196 | 45 | 저체중 |
| 2 | 171 | 51 | 저체중 |
| 3 | 190 | 44 | 저체중 |
| 4 | 142 | 76 | 비만 |
| ... | ... | ... | ... |
| 9995 | 155 | 69 | 비만 |
| 9996 | 172 | 74 | 비만 |
| 9997 | 168 | 43 | 저체중 |
| 9998 | 192 | 76 | 정상체중 |
| 9999 | 121 | 74 | 비만 |
10000 rows × 3 columns
# 데이터와 레이블 분리 변수 선언
X = tbl[['height', 'weight']]
y = tbl['label']
# 데이터셋 분리 (학습데이터:검증데이터 = 7:3)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
# 알고리즘 데이터를 학습시키고 예측하기
model = svm.SVC(kernel='linear')
model.fit(X_train, y_train)
SVC(kernel='linear')# 예측하기
pred = model.predict(X_test)
print(pred)
pred_me = model.predict([['165', '47']])
print(pred_me)
['정상체중' '비만' '비만' ... '저체중' '비만' '비만']
['저체중']
# 정확도
print(model.score(X_test, y_test))
0.986
# 검증하기
print(metrics.accuracy_score(y_test, pred))
0.986
# 그래프 - jointplot
sns.jointplot(x='weight', y='height', data=X_test, kind='hex');

# 그래프 - kdeplot
sns.kdeplot(x='weight', y='height', data=X_test, shade=True);

# 그래프 - pairplot
pair = sns.PairGrid(X_test)
pair.map_upper(sns.regplot)
pair.map_lower(sns.kdeplot)
pair.map_diag(sns.histplot)
<seaborn.axisgrid.PairGrid at 0x12675d1abb0>
# 랜덤포레스트 모델
from sklearn.ensemble import RandomForestClassifier
# 2000개의 트리를 형성
# : 주어진 데이터 세트에서 무작위로 중복을 허용하여 n개를 선택(부트스트랩)하여 의사결정트리 갯수만큼 학습
classifier = RandomForestClassifier(n_estimators=2000)
# 학습 및 정확도 확인
classifier.fit(X_train, y_train)
score = classifier.score(X_test, y_test)
print(score)
0.9923333333333333
# 예측하기
pred = classifier.predict(X_test)
print(pred)
['정상체중' '비만' '비만' ... '저체중' '비만' '비만']