2021. 1. 15. 13:56ㆍ교육과정/KOSMO
키워드 : 파이썬에서 CSV 데이터를 DB 에 입출력 하기
****
0. 파이썬에서 메인함수 역할을 해주는 if __name__ :
| if __name__ : 은 다른 프로그램의 main() 역할을 한다. Ex02_csv_insert.py 에서 실행하면 __name__ 변수에 __main__ 값이 들어가고, 다른 파일에서 이 파일을 실행하면 파일명과 동일한 Ex02_csv_insert 라는 값이 들어간다. 즉, __name__ 에 __main__ 이라고 되어 있으면 내가 나를 실행한 것이고, __name__ 에 파일명이 들어가 있으면 다른 곳에서 나를 실행한 것이다. |
1. 파이썬 CSV 의 데이터를 DB로 입출력하기 (1) - 테이블 생성
(1) 파이썬에서 DB와 연동하기 위한 createDBtable( ) 함수를 작성한다.
SQL 을 여러 개 전송하려면 cursor 로 실행한 뒤 새로운 SQL 을 이어서 작성하고 반복하도록 만들면 된다.
import cx_Oracle as oci
# 1. DB 테이블 생성
def createDBtable():
# 1. 연결객체 얻어오기
conn = oci.connect('scott/tiger@192.168.0.17:1521/orcl')
# 2. 커서 얻어오기
cursor = conn.cursor()
# 3. sql 문장 만들기
sql = ""
# 4. 실행하기
cursor.execute(sql)
sql2 = ""
cursor.execute(sql2)
# 5. 커서 닫기
cursor.close()
# 6. 연결 닫기
conn.close()
if __name__ == '__main__':
# 1. DB 테이블 생성
createDBtable()
(2) SQL 작성시 " " 대신 """ """ 를 사용하면 중간에 + 연산자를 사용하지 않아도 SQL 작성이 가능하다.
DB에서 테이블과 시퀀스를 생성하도록 SQL을 작성한다.
sql = """
CREATE TABLE supply(
id integer primary key,
supplier_name varchar(30),
invoice_number varchar(20),
part_number varchar(20),
cost integer,
purchase_date date
)
"""
cursor.execute(sql)
sql2 = "CREATE SEQUENCE seq_supply_id"
cursor.execute(sql2)
(3) 오라클에서 테이블과 시퀀스가 생성되었는지 확인 후,
createDBtable( ) 함수는 다시 실행할 필요 없으므로 주석처리한다.

if __name__ == '__main__':
# 1. DB 테이블 생성
# createDBtable()
< 파이썬에서 오라클 테이블 생성 하기 >
import cx_Oracle as oci
# 1. DB 테이블 생성
def createDBtable():
# 1. 연결객체 얻어오기
conn = oci.connect('scott/tiger@192.168.0.17:1521/orcl')
# 2. 커서 얻어오기
cursor = conn.cursor()
# 3. sql 문장 만들기
sql = """
CREATE TABLE supply(
id integer primary key,
supplier_name varchar(30),
invoice_number varchar(20),
part_number varchar(20),
cost integer,
purchase_date date
)
"""
sql2 = "CREATE SEQUENCE seq_supply_id"
# 4. 실행하기
cursor.execute(sql)
cursor.execute(sql2)
# 5. 커서 닫기
cursor.close()
# 6. 연결 닫기
conn.close()
# -----------------------------------------------------
if __name__ == '__main__':
# 1. DB 테이블 생성
createDBtable()
2. 파이썬 CSV 의 데이터를 DB로 입출력하기 (2) - 데이터 입력 (1) 원본 그대로 입력하기
(1) 메인에서 데이터 입력을 위해 사용할 saveDBtable( ) 함수가 수행되도록 추가한다.
if __name__ == '__main__':
# 1. DB 테이블 생성
# createDBtable()
# 2. 데이터 입력
saveDBtable()
(2) saveDBtable( ) 함수의 내용을 작성한다.
★ SQL 작성시 컬럼명을 모두 기술해야 나중에 새로운 컬럼이 추가되더라도 에러를 유발하지 않는다. ★
# 2. 데이터 입력
def saveDBtable():
conn = oci.connect('scott/tiger@192.168.0.17:1521/orcl')
cursor = conn.cursor()
sql = """
INSERT INTO
supply(id, supplier_name, invoice_number,
part_number, cost, purchase_date)
VALUES(seq_supply_id.nextval, :0, :1, :2, :3, :4)
"""
cursor.execute(sql)
cursor.close()
conn.close()
(3) 읽어올 파일을 지정하고, csv 파일을 읽기 위해 필요한 모듈을 import 한다.
open( ) 함수에서는 데이터를 읽기 위해 ' r ' 옵션을 입력한다.
import csv
...
if __name__ == '__main__':
...
# 2. 데이터 입력
filename = '../files/supply.csv'
file = open(filename, 'r')
saveDBtable()
(4) csv 파일에서는 , 로 데이터를 구분하고 있기 때문에,
reader( ) 함수로 csv 파일을 읽을 때 delimiter 구분자로 콤마 , 를 넣어준다.
filename = '../files/supply.csv'
file = open(filename, 'r')
datas = csv.reader(file, delimiter=',')
(5) csv 파일로부터 데이터를 잘 읽어오는지 확인하기 위해 반복문을 사용하여 출력한다.
saveDBtable( ) 함수는 일단 실행하지 않도록 주석처리한다.
datas = csv.reader(file, delimiter=',')
for row in datas:
print(row)
# saveDBtable()
(6) 파일을 실행했을 때 첫 번째로 출력되는 리스트는 데이터가 아닌 제목에 해당하므로,
첫 번째 리스트는 제외하고 출력하도록 처리해야 한다.
['Supplier Name,Invoice Number,Part Number,Cost,Purchase Date']
['Samsung,1001,2521,50000,2025-01-01']
['Samsung,1001,2521,50000,2025-01-01']
....
(8) next( ) 함수를 사용하여 1줄만 읽은 뒤, 아무 일도 하지 않고 다음줄부터 반복문에 들어가도록 작성한다.
( 1줄 읽은 뒤 아무런 작업을 수행하지 않으므로 제목을 지우는 결과가 나타난다. )
filename = '../files/supply.csv'
file = open(filename, 'r')
datas = csv.reader(file, delimiter='.')
next(datas, None) # 한 줄을 읽은 뒤 아무 일도 하지 않음
for row in datas:
print(row)
# saveDBtable()
(7) 다시 한 번 파일을 실행하여 csv 파일을 읽은 결과에서 첫번째 리스트를 제외하고 출력되는지 확인한다.
['Samsung', '1001', '2521', '50000', '2025-01-01']
['Samsung', '1001', '2521', '50000', '2025-01-01']
['Samsung', '1001', '5522', '70000', '2025-01-01']
['LG', '10-1111', '50001', '35000', '2025-02-02']
....
(8) csv 파일을 1줄씩 읽을 때마다 saveDBtable( ) 함수가 수행되도록 반복문 안에 넣고, 인자를 받도록 수정한다.
filename = '../files/supply.csv'
file = open(filename, 'r')
datas = csv.reader(file, delimiter='.')
next(datas, None) # 한 줄을 읽은 뒤, 아무 일도 하지 않음
for row in datas:
print(row)
saveDBtable(row)
(9) 함수를 정의하는 곳에서도 인자를 받고,
커서 객체를 통해 SQL 전송시 인자의 데이터를 함께 보내도록 수정한다.
def saveDBtable(data):
....
cursor.execute(sql, data)
....
(10) 실행 후 오라클 DB 에 데이터가 입력되는지 확인해보면,
커밋을 하지 않았기 때문에 파이썬에서 에러가 없었음에도 실제 DB 입력이 되지 않는다.
SQL 전송 후 커밋을 하도록 saveDBtable( ) 함수의 내용을 수정한다.
def saveDBtable(data):
....
cursor.execute(sql, data)
conn.commit()
....
(11) 다시 실행해보면 오라클 DB 에 정상적으로 csv 의 데이터가 입력되어 있음을 확인할 수 있다.
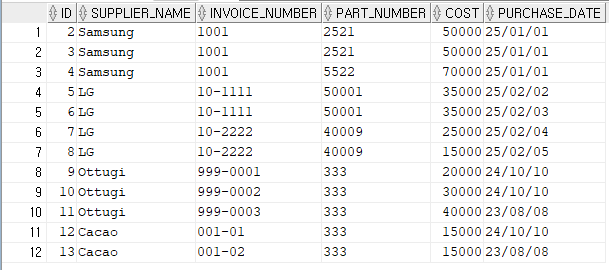
< 파이썬에서 오라클 테이블에 데이터 입력하기 >
import cx_Oracle as oci
# 2. 데이터 입력 (1)
def saveDBtable(data):
conn = oci.connect('scott/tiger@192.168.0.17:1521/orcl')
cursor = conn.cursor()
sql = """
INSERT INTO
supply(id, supplier_name, invoice_number,
part_number, cost, purchase_date)
VALUES(seq_supply_id.nextval, :0, :1, :2, :3, :4)
"""
cursor.execute(sql, data)
conn.commit() # ***************
cursor.close()
conn.close()
# -----------------------------------------------------
if __name__ == '__main__':
# 1. DB 테이블 생성
# createDBtable()
# 2. 데이터 입력
filename = '../files/supply.csv'
file = open(filename, 'r')
datas = csv.reader(file, delimiter=',')
next(datas, None) # 한 줄을 읽은 뒤, 아무 일도 하지 않음
for row in datas:
print(row)
saveDBtable(row)
3. 파이썬 CSV 의 데이터를 DB로 입출력하기 (3) - 데이터 입력 (2) 원본을 가공하여 입력하기
(1) 메인에서 saveDBtable2( ) 라는 함수를 실행하도록 변경하고,
기존 saveDBtable( ) 의 내용을 복사하여 saveDBtable2( ) 함수를 정의한다.
def saveDBtable2(data):
conn = oci.connect('scott/tiger@192.168.0.17:1521/orcl')
cursor = conn.cursor()
....
if __name__ == '__main__':
# 2. 데이터 입력
filename = '../files/supply.csv'
file = open(filename, 'r')
datas = csv.reader(file, delimiter=',')
next(datas, None) # 한 줄을 읽은 뒤, 아무 일도 하지 않음
for row in datas:
print(row)
saveDBtable2(row)
(2) 경우에 따라 원본 데이터를 가공해서 DB 에 입력해야 하는 상황이 있다.
리스트 단위로 읽어오는 데이터를 각 변수에 나누어 담아, 데이터를 가공할 수 있는 여건을 마련한다.
| * 데이터를 가공해서 보내야 할 경우에는 임시로 사용하는 변수명임을 명시하는 편이 좋다. (v_xxx 등) * 각 변수로 나누어 지정함으로써 함수 내부 또는 SQL문에서 데이터를 가공할 수 있는 여건을 마련한다. |
# 2. 데이터 입력 (2)
def saveDBtable2(data):
...
v_name = data[0] + ' 가공'
v_invoice = data[1] + ' 가공'
v_part = data[2] + ' 가공'
v_cost = data[3]
v_date = data[4]
....
(3) SQL 전송시 가공된 데이터가 들어있는 변수를 인자로 넣되, 튜플 구조로 묶어준다.
변수는 순서대로 기입한다. ( 순서를 지키지 않을 경우 데이터가 뒤바뀐 채로 DB 에 입력된다. )
| [ 주의할 점 ] 변수가 하나라면?? ... 변수가 하나일지라도 튜플로 만들어야 한다. cursor.excute(sql, (v_name , ) ) |
# 2. 데이터 입력 (2)
def saveDBtable2(data):
...
cursor.execute(sql, (v_name, v_invoice, v_part, v_cost, v_date))
conn.commit()
...
(4) SQL 에서도 변수값으로 데이터가 입력되도록 작성하되,
데이터베이스에서는 단어와 변수를 구별하기 위해 콜론 : 을 사용하므로
변수명 앞에 콜론 : 을 붙인다. (PL/SQL 방식)
| * PL/SQL : 프로그램 언어의 특성을 수용한 SQL 의 확장된 개념 |
# 2. 데이터 입력 (2)
def saveDBtable2(data):
....
sql = """
INSERT INTO
supply(id, supplier_name, invoice_number,
part_number, cost, purchase_date)
VALUES(seq_supply_id.nextval, :v_name, :v_invoice,
:v_part, :v_cost, :v_date)
"""
....(+)
콜론 : 이후에 변수명 대신 다른 문자를 넣어도 갯수만 맞으면 동일하게 실행되지만,
혼동을 피하기 위해서 변수명을 사용하는 편이 좋다.
sql = """
INSERT INTO
supply(id, supplier_name, invoice_number,
part_number, cost, purchase_date)
VALUES(seq_supply_id.nextval, :a, :0,
:v_part, :v_cost, :v_date)
"""
(5) 파일을 실행 후, DB 에 가공된 데이터가 입력되었음을 확인할 수 있다.

< 파이썬에서 오라클 테이블에 가공된 데이터 입력하기 >
import cx_Oracle as oci
# 2. 데이터 입력 (1)
def saveDBtable(data):
conn = oci.connect('scott/tiger@192.168.0.17:1521/orcl')
cursor = conn.cursor()
sql = """
INSERT INTO
supply(id, supplier_name, invoice_number,
part_number, cost, purchase_date)
VALUES(seq_supply_id.nextval, :0, :1, :2, :3, :4)
"""
cursor.execute(sql, data)
conn.commit() # ***************
cursor.close()
conn.close()
# -----------------------------------------------------
if __name__ == '__main__':
# 1. DB 테이블 생성
# createDBtable()
# 2. 데이터 입력
filename = '../files/supply.csv'
file = open(filename, 'r')
datas = csv.reader(file, delimiter=',')
next(datas, None) # 한 줄을 읽은 뒤, 아무 일도 하지 않음
for row in datas:
print(row)
saveDBtable2(row)
4. 파이썬 CSV 의 데이터를 DB로 입출력하기 (4) - 데이터 출력
(1) 메인에서 데이터 출력을 위한 viewDBtable( ) 함수를 추가하되,
출력하려는 테이블명을 인자로 가져가도록 작성한다.
if __name__ == '__main__':
....
# 3. 데이터 출력
viewDBtable('supply') # 출력하려는 테이블 명을 기입한다.
(2) viewDBtable( ) 함수가 정의될 때 인자를 받아가도록 기본 틀을 만든다.
# 3. 데이터 출력
def viewDBtable(table):
conn = oci.connect('scott/tiger@192.168.0.17:1521/orcl')
cursor = conn.cursor()
sql = " "
cursor.execute(sql)
cursor.close()
conn.close()
(3) viewDBtable( ) 함수에서 인자로 받은 테이블명이 SQL 문에서 데이터를 가져올 때 사용될 수 있도록 작성한다.
# 3. 데이터 출력
def viewDBtable(table):
....
# 방법 1
sql = "SELECT * FROM " + table
# 방법 2
sql = "SELECT * FROM ", table
# 방법 3
sql = "SELECT * FROM {}".format(table)
....(+) 방법 3 과 같이 format( ) 함수를 사용할 경우, 복잡해질 수 있는 파이썬에서의 SQL 을 깔끔하게 만들 수 있다.
sql = "SELECT * FROM {} where {}= {}".format(table, x, a)
(4) fetchall( ) 함수를 사용하여 SELECT 문으로 검색한 결과를 모두 가져온 뒤, 변수 rows 에 담는다.
# 3. 데이터 출력
def viewDBtable(table):
....
rows = cursor.fetchall()
....
(5) 변수 rows 에 들어있는 데이터는 여러 줄로 이루어져 있으므로, for 반복문을 사용하여 list 자료형으로 출력된다.
# 3. 데이터 출력
def viewDBtable(table):
....
rows = cursor.fetchall()
for row in rows:
print(row)
# 실행결과
'''
(2, 'Samsung', '1001', '2521', 50000, datetime.datetime(2025, 1, 1, 0, 0))
(3, 'Samsung', '1001', '2521', 50000, datetime.datetime(2025, 1, 1, 0, 0))
(4, 'Samsung', '1001', '5522', 70000, datetime.datetime(2025, 1, 1, 0, 0))
(5, 'LG', '10-1111', '50001', 35000, datetime.datetime(2025, 2, 2, 0, 0))
'''(+)
for 반복문에서 rows 대신 cursor.execute(sql) 자체를 넣어서 출력할 수도 있으나,
이 경우, 출력 데이터의 자료형이 cx_Oracle.Cursor 가 된다.
# 3. 데이터 출력
def viewDBtable(table):
....
cursor.execute(sql)
rows = cursor.fetchall()
....
print(type(cursor.execute(sql)))
print(type(cursor.fetchall()))
print(type(rows))
# 실행결과
'''
<class 'cx_Oracle.Cursor'>
<class 'list'>
<class 'list'>
'''
(6) viewDBtacle( ) 함수를 호출하는 메인에서 데이터 출력하기 위해
함수를 정의하는 곳에서는 결과를 리턴하고, 호출하는 곳에서는 값을 받도록 수정한다.
# 3. 데이터 출력
def viewDBtable(table):
....
rows = cursor.fetchall()
return rows
# -----------------------------------------------------
if __name__ == '__main__':
....
rows = viewDBtable('supply')
(7) 판다스 라이브러리를 사용하여 테이블을 출력한다.
import pandas as pd① 판다스 라이브러리에서는 출력해야 할 데이터가 많은 경우, 앞 행 일부와 뒷 행 일부만 보여준다.
if __name__ == '__main__':
....
rows = viewDBtable('supply')
print(pd.DataFrame(rows))
# 실행결과
'''
0 1 2 3 4 5
0 2 Samsung 1001 2521 50000 2025-01-01
1 3 Samsung 1001 2521 50000 2025-01-01
2 4 Samsung 1001 5522 70000 2025-01-01
3 5 LG 10-1111 50001 35000 2025-02-02
4 6 LG 10-1111 50001 35000 2025-02-03
.. .. ... ... ... ... ...
79 81 Ottugi 999-0001 가공 333 가공 20000 2024-10-10
80 82 Ottugi 999-0002 가공 333 가공 30000 2024-10-10
81 83 Ottugi 999-0003 가공 333 가공 40000 2023-08-08
82 84 Cacao 001-01 가공 333 가공 15000 2024-10-10
83 85 Cacao 001-02 가공 333 가공 15000 2023-08-08
[84 rows x 6 columns]
Process finished with exit code 0
'''② head( ) 또는 tail( ) 함수를 추가 적용하여 출력 범위를 변경할 수 있다.
if __name__ == '__main__':
....
rows = viewDBtable('supply')
print(pd.DataFrame(rows).head(2))
# 실행결과
'''
0 1 2 3 4 5
0 2 Samsung 1001 2521 50000 2025-01-01
1 3 Samsung 1001 2521 50000 2025-01-01
...
또는
if __name__ == '__main__':
....
rows = viewDBtable('supply')
print(pd.DataFrame(rows).tail(3))
# 실행결과
'''
0 1 2 3 4 5
81 83 Ottugi 999-0003 가공 333 가공 40000 2023-08-08
82 84 Cacao 001-01 가공 333 가공 15000 2024-10-10
83 85 Cacao 001-02 가공 333 가공 15000 2023-08-08
...
③ 옵션을 부여해서 출력범위를 제한할 수 있다.
if __name__ == '__main__':
....
rows = viewDBtable('supply')
pd.set_option('display.max_columns', 3)
pd.set_option('display.max_rows', 5)
print(pd.DataFrame(rows))
# 실행결과
'''
0 ... 5
0 2 ... 2025-01-01
1 3 ... 2025-01-01
.. .. ... ...
82 84 ... 2024-10-10
83 85 ... 2023-08-08
[84 rows x 6 columns]
...
(+) f 스트링을 사용하여 특정 열의 데이터를 출력할 수 있다.
if __name__ == '__main__':
....
rows = viewDBtable('supply')
for a in rows:
print(f'{a[:]}') # 모든 데이터 출력
print(f'{a[:3]}') # 3번째 전까지의 데이터 출력
# 실행결과
'''
(2, 'Samsung', '1001')
(3, 'Samsung', '1001')
(4, 'Samsung', '1001')
...
< 파이썬에서 오라클 테이블의 데이터 출력하기 >
'''
다른 프로그램의 main() 역할
Ex02_csv_insert.py 에서 실행하면 __name__ 변수에 __main__ 값이 들어가고,
다른 파일에서 이 파일을 실행하면 파일명과 동일한 Ex02_csv_insert 라는 값이 들어간다.
즉, __name__ 에 __main__ 이라고 되어 있으면 내가 나를 실행한 것이고,
__name__ 에 파일명이 들어가 있으면 다른 곳에서 나를 실행한 것이다.
'''
import cx_Oracle as oci
import csv
import pandas as pd
# 1. DB 테이블 생성
def createDBtable():
with oci.connect('scott/tiger@192.168.0.17:1521/orcl') as conn:
with conn.cursor() as cursor:
sql = """
CREATE TABLE supply(
id integer primary key,
supplier_name varchar(30),
invoice_number varchar(20),
part_number varchar(20),
cost integer,
purchase_date date
)
"""
cursor.execute(sql)
sql2 = """
CREATE SEQUENCE seq_supply_id
"""
cursor.execute(sql2)
# 2. 데이터 입력 (1) 원본데이터
def saveDBtable(data):
with oci.connect('scott/tiger@192.168.0.17:1521/orcl') as conn:
with conn.cursor() as cursor:
sql = """
INSERT INTO
supply(id, supplier_name, invoice_number,
part_number, cost, purchase_date)
VALUES(seq_supply_id.nextval, :0, :1, :2, :3, :4)
"""
cursor.execute(sql, data)
conn.commit() # ***************
# 2. 데이터 입력 (2) 가공데이터
def saveDBtable2(data):
with oci.connect('scott/tiger@192.168.0.17:1521/orcl') as conn:
with conn.cursor() as cursor:
sql = """
INSERT INTO
supply(id, supplier_name, invoice_number,
part_number, cost, purchase_date)
VALUES(seq_supply_id.nextval, :a, :0,
:v_part, :v_cost, :v_date)
"""
v_name = data[0]
v_invoice = data[1] + ' 가공'
v_part = data[2] + ' 가공'
v_cost = data[3]
v_date = data[4]
cursor.execute(sql, (v_name, v_invoice, v_part, v_cost, v_date))
conn.commit()
# 3. 데이터 출력
def viewDBtable(table):
conn = oci.connect('scott/tiger@192.168.0.17:1521/orcl')
cursor = conn.cursor()
sql = "SELECT * FROM {}".format(table)
cursor.execute(sql)
rows = cursor.fetchall()
return rows
# for문을 사용하여 데이터 출력
# for row in rows:
# print(row)
# -----------------------------------------------------
if __name__ == '__main__':
# 1. DB 테이블 생성
# createDBtable()
# 2. 데이터 입력
filename = '../files/supply.csv'
file = open(filename, 'r')
datas = csv.reader(file, delimiter=',')
next(datas, None) # 한 줄을 읽어서 아무 일도 하지 않음
for row in datas:
# print(row)
# saveDBtable(row)
# saveDBtable2(row)
pass
# 3. 데이터 출력
rows = viewDBtable('supply') # 출력하려는 테이블 명을 기입한다.
for a in rows:
print(f'{a[1]}')
# pd.set_option('display.max_columns', 3)
# pd.set_option('display.max_rows', 5)
# print(pd.DataFrame(rows).head(2))
# print(pd.DataFrame(rows).tail(2))
print(pd.DataFrame(rows))