2021. 1. 18. 11:21ㆍ교육과정/KOSMO
키워드 : 데이터 과학 / 하둡 / HDFS / Virtual Box 설치 / PuTTy 에서 Virtual Box 접속 / MobaXterm 설치 / 하둡설치(1)
****
1. 데이터 과학
- 데이터란?
: 과거의 추상적인 개념 -> 기술적이고 사실적인 의미로 변화
: 데이터를 단순한 객체로서 가치 + 다른 객체와의 상호관계 속에서 가치
: 객관적 사실이라는 존재적 특성 + 추론/예측/전망/추정을 위한 근거
- data : 데이터 자체로는 의미가 중요하지 않은 객관적인 사실
- information : 데이터 간 연관 관계 속에서 의미 도출된 것
- knowledge : 정보를 구조화하여 유의미한 정보로 분류 + 개인 경험 결합
- wisdom : 지식의 축적 + 아이디어
- 데이터 과학자(Data Scientist)는 통계학자나 비즈니스 인텔리전스 분석가보다 컨퓨팅이나 알고리즘 구축 능력을 더 많이 언습한다.
- 데이터의 양이 계속 증가하고 활용도가 높아짐에 따라 데이터 과학자와 빅데이터 프로젝트는 필연적으로 엮이게 되었다.
---- 현실 세계 <----> 사물인터넷 <----> 빅데이터 ----
>> 현실 세계의 정보가 센서를 통해 빅데이터화되고, 빅데이터가 사물인터넷을 통해 현실 세계에 영향을 미친다.
- 빅데이터의 특성 (3V)
* Volume (Data Quantity) : Terra, Peta, Exa, Zetta, Yotta 단위 데이터 양
* Variety (Data Types) : 정형, 비정형 데이터 종류
* Velocity (Data Speed) : 데이터 발생 속도
- 빅데이터의 특성 (4V)
* Value : 가치
` 데이터 발생 속도 (Data Speed)
: 하루 250경 바이트의 비정형 데이터
: 매달 10억여 개의 트윗
: 매달 350억여 개의 페이스북 메시지
: 1조대 이상의 모바일 기기
` 데이터의 다양성 (Data Types)
: 정형 데이터 - 정형화된 스키마를 가진 데이터 - RDB
: 반정형 데이터 - 메타 구조를 가지는 데이터 - XML / JSON / 웹로그 / 센서데이터
: 비정형 데이터 - 이미지, 음성, 동영상, IoT 사물 인터넷에서 발생하는 데이터 - 이진파일 / 텍스트 / 동영상 / 이미지
- 빅데이터 시스템
: 대용량 데이터를 분산 병렬 처리하고 관리하는 시스템
:: 실시간 데이터를 처리
:: 많은 데이터를 저비용으로 처리
:: 결함 허용이 되는 시스템이 필요함 (결함이 발생해도 전체 시스템에 영향이 없는 구조)
:: 분산 처리가 가능해야 함
- 저비용 시스템
: 성능이 낮은 서버로 시스템 구성이 가능 (Scale Up 대신 Scale out --- more smaller servers)
: 오픈 소스나 상용 소프트웨어 도입으로 라이선스 비용 절감
: 처리할 데이터 구조, 처리량에 따라 적절한 비용의 툴 선택 가능
※ 하둡 : 맵리듀스를 핵심으로 하여 저비용 하드웨어로 대용량 데이터를 처리할 수 있는 오픈 소스 플랫폼
- 대표적인 하둡 배포판
: 아파치 하둡 배포판
: 맵알 하둡 배포판
: 클라우데라 하둡 배포판
: 호튼웍스 하둡 배포판
>>> 각 상황과 종류에 따라 처리 시스템을 검증하고 각 특장점을 비교하고 결정
* 아파치 하둡 에코 시스템

* 클라우데라 하둡(CDH) 에코 시스템

* 호튼웍스(Hortonworks) 에코 시스템

※ 빅데이터 처리 환경 구축
>> 개별적인 시스템 구축 방식
>> 클라우드 컴퓨팅을 사용하는 방식 (Amazon AWS , MS Azure)

* 빅데이터 프로세스

< 하둡 History >
1980~90 : 인공지능 체스
2003 : GFS
2004 : 맵리듀스 (제프리 딘)
--------------------------------------
2005 : nutch 프로젝트 (대용량 ) : 더그 커팅
2006 : 야후 하둡 프로젝트
2008~9 : 클라우데라
호트웍스 (현재는 두 회사가 합병)
2011 : apache 프로젝트
* 더그 커팅 : 검새엔진 (아파치 루신) ---> elestic search
* 딥러닝(인공지능) : 텐서플로2
* spark - java (X) / python {python) / scala 로 구축 가능
2. 하둡
(1) 하둡 클러스터 동작 방식
| - 독립 모드 ( Standalone Mode ) - 의사 분산 모드 ( Pseudo-distributed Mode ) - 완전 분산 모드 ( Fully distributed Mode ) |
① 독립모드
: 맥리듀스 개발 테스트를 하는 동안 사용하는 모드
: HDFS를 사용하지 않고 로컬 파일 시스템을 사용
② 의사 분산 모드
: 1대의 컴퓨터를 사용해서 가상 분산 운영 모드로 사용
: 작은 규모의 클러스터를 테스트, 디버깅 등 하는 경우에 사용
: HDFS 사용
③ 완전 분산 모드
: 하둡 데몬 프로세스가 클러스터로 구성된 여러 개의 컴퓨터에 나누어 동작
: 데이터들은 실제 데이터 노드에 분산 저장되며 이들에 대한 메타 정보는 네임노드에서 관리하는 운영 모드

| ` 빅데이터 처리 프레임워크 ` HDFS + MapReduce ` 다양한 에코 시스템으로 구성 ` 결함 허용 시스템 ` 데이터 블록의 복사본을 중복 저장 |
(2) 하둡의 구성 요소
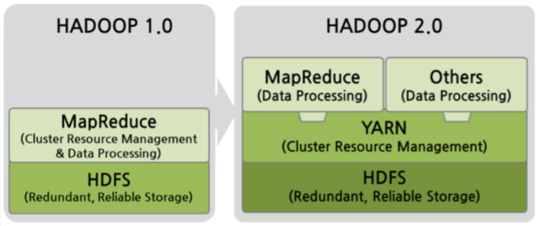
(3) 하둡 클러스터 (v1)
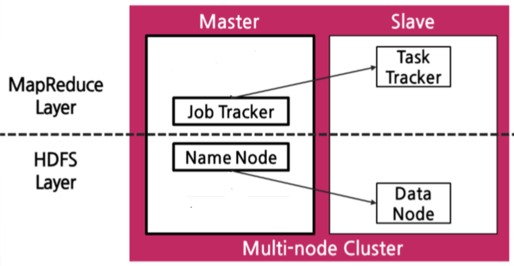


(3) 하둡 클러스터 (v2)

(4) 하둡의 단점
- HDFS 에 저장된 데이터를 변경 불가
- 실시간 데이터 분석 같이 신속하게 처리해야 하는 작업에는 부적합
- 너무 많은 버전과 부실한 서포트
- 설정의 어려움
(5) 하둡의 과제
- 하둡은 100% 완벽한 시스템이 아니다.
- 하둡 관련 전문 업체가 부족한 것이 현실이다.
- 작은 규모로 하둡을 구축하고 기술력과 노하루를 쌓고 기업 스스로 해결할 수 있는 방향을 찾는 것이 하둡을 도입하는 가장 올바른 방향이다.
3. HDFS


4. Virtual Box 설치
(1) Virtual Box 설치 ( 현재 6.0 버전이지만 5.2 버전 다운로드 )
① https://www.virtualbox.org/ 접속
② Download 클릭 > VirtualBox 5.2 builds 클릭
③ Windows hosts 클릭
④ 다운 받은 파일 설치, 설치 완료

(2) Vagrant (베이그랜트) 설치
|
경량화된 Virtual machine 관리 서비스이다. |
① https://www.vagrantup.com/ 접속 - Download 클릭 - Download Order Versions 를 클릭


② vagrant_2.2.2 버전 - 64bit 윈도우 설치용으로 다운


③ 다음 경로로 저장이 되며, 설치 완료 후 리부팅

④ 관리자 권한의 CMD에서, 루트 경로 이동 후 베이그랜트가 설치된 HashCorp 폴더로 이동

⑤ vagrarnt init 명령어 입력 후 설치경로에 생성된 Vagrantfile 파일을 열어
모든 내용을 제거 후 다음 내용을 붙여넣는다.
(OS 설치에 관한 사항)

VAGRANTFILE_API_VERSION = "2"
Vagrant.configure(VAGRANTFILE_API_VERSION) do |config|
config.ssh.insert_key = false
config.vm.define :nn01 do |nn01_config|
nn01_config.vm.box = "centos/7"
nn01_config.vm.hostname = "nn01"
nn01_config.vm.network "private_network", ip: "192.168.56.101"
nn01_config.vm.provider :virtualbox do |vb|
vb.name = "nn01"
vb.memory = "4096"
end
end
config.vm.define :dn01 do |dn01_config|
dn01_config.vm.box = "centos/7"
dn01_config.vm.hostname = "dn01"
dn01_config.vm.network "private_network", ip: "192.168.56.102"
dn01_config.vm.provider :virtualbox do |vb|
vb.name = "dn01"
vb.memory = "4096"
end
end
config.vm.define :dn02 do |dn02_config|
dn02_config.vm.box = "centos/7"
dn02_config.vm.hostname = "dn02"
dn02_config.vm.network "private_network", ip: "192.168.56.103"
dn02_config.vm.provider :virtualbox do |vb|
vb.name = "dn02"
vb.memory = "4096"
end
end
end
⑥ dir 명령어로 폴더의 세부사항을 확인

⑦ Vagrantfile 이 존재하는 경로에서 vagrant up 명령어로 vagrant 실행하여 CentOS7을 3개 설치
>> VirtualBox에 nn01, dn01, dn02 서버가 생성됨

⑧ 정상적으로 설치완료시 . vagrant / machines 폴더에 CentOS가 3개 생성된 것을 확인할 수 있다.
(중간에 CMD 창을 클릭하면 안 된다. 클릭으로 인해 블록이 생길 경우 에러가 발생할 수 있다. )


⑨ 관리자권한으로 Virtual Box 실행하여 nn01 / dn01 / dn02 가상 머신이 생성된 것을 확인
자동으로 2개의 계정이 생성되며, 우선 root 계정으로 접속 확인

| 생성된 계정 | root | vagrant |
| vagrant | vagrant |
⑩ www.virtualbox.org/wiki/Download_Old_Builds_5_2 에 접속하여 Extension Pack 다운로드

⑪ 메뉴 - 파일 - 환경설정 - 확장 - " + " 클릭 - 다운받은 확장팩 선택 후 설치


⑫ 3개의 CentOS에 root 계정으로 정상적으로 접속 가능

⑬ ip addr 명령어로 ip 주소를 확인할 수 있다.

⑭ 마우스 잡기 설정 해제 방법 : 메뉴 - 파일 - 환경설정 - 입력 - 가상머신 - 호스트 키 조합 변경 후 확인

(3) PuTTy 에서 Virtual box 에 설치된 서버에 접속하기
① ip 주소와 OS 이름을 저장한 뒤 root 계정으로 접속시도시 에러가 발생한다.

② 먼저 nn01 OS 에서 vi 에디터로 sshd_config 파일을 수정한다.
[root@nn01 ~]# vi /etc/ssh/sshd_config:set nu 로 라인수 확인
/Password 로 검색
i 로 입력모드
ESC 로 명령모드
:00 (라인수)로 즉각 이동
no를 yes 로 수정 후 :wq로 저장 및 나가기

③ PuTTy로 3가지 OS 접속이 모두 가능한지 확인
(4) 리눅스 작업을 편리하게 해주는 도구인 MobaXterm 설치
① https://mobaxterm.mobatek.net 접속 - Download - 무료버전 선택
- MobaXterm Home Edition v20.6 (Portable edition) 클릭 - 압축해제

② MobaXterm 실행
- 작업 가능한 OS를 열고 상단의 "Multi-execution mode" 로 입력하면 모든 창에 동시 입력이 가능하다.

③ 최소 설치를 했으므로 필요한 패키지들을 추가하기 위해 yum update 명령어로 패키지 업데이트를 진행한다.
[root@nn01 ~]# yum update
Loaded plugins: fastestmirror
Determining fastest mirrors
* base: mirror.navercorp.com
* extras: mirror.navercorp.com
....
Transaction Summary
=====================================
Install 1 Package (+1 Dependent p ackage)
Upgrade 117 Packages
Total download size: 246 M
Is this ok [y/d/N]: y
Downloading packages:
....
yum-utils.noarch 0:1.1.31-54.el7_8
Complete!
④ yum install telnet svn git nc ntp wget vim net-tools 명령어로 자주 스는 프로그램을 설치한다.
[root@nn01 ~]# yum install telnet svn git nc ntp wget vim net-tools
Loaded plugins: fastestmirror
Loading mirror speeds from cached hos tfile
....
vim-common.x86_64 2:7.4.629-8.el7_9
vim-filesystem.x86_64 2:7.4.629-8.e l7_9
Complete!
⑤ 추가 작업으로 방화벽을 해제한다. (보안이 취약해지므로 실습에서만 편의적으로 해제한다. )
[root@nn01 ~]# systemctl stop firewalld
[root@nn01 ~]# systemctl disable firewalld
5. 하둡 설치
(1) JDK, Hadoop 설치
※ Master, Slave 역할
| nn01 | Master (NameNode, SecondaryNamenode, ResourceManager) |
| dn01 | Slave (DataNode, NodeManager) |
| dn02 | Slave (DataNode, NodeManager) |
※ 현재 최소 버전이라 JAVA 가 설치되어 있지 않다.
[root@nn01 ~]# which java
/usr/bin/which: no java in (/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin)
※ MobaXterm을 사용하여 root 계정에서 반복동작을 줄이고 JAVA를 설치할 수 있다.
(1) protobuf 설치
|
구글에서 공개한 오픈소스 직렬화 라이브러리 |
① root 계정에서 설치 전 필요한 툴을 다운 받는다.
[root@nn01 ~]# yum install -y autoconf automake libtool curl gcc-c++ unzip
② protobuf 설치
[root@nn01 ~]# cd /tmp
[root@nn01 tmp]# wget https://github.com/protocolbuffers/protobuf/releases/download/v2.5.0/protobuf-2.5.0.tar.gz
[root@nn01 tmp]# tar -zxvf protobuf-2.5.0.tar.gz
[root@nn01 tmp]# mv protobuf-2.5.0 /opt/
[root@nn01 tmp]# ls /opt/ # 이동되었는지 확인
protobuf-2.5.0
③ protobuf 폴더로 이동
[root@nn01 tmp]# cd /opt/protobuf-2.5.0/
④ configure 파일 실행
( 여기서 에러가 발생하면 ./configure에서 안되는 것임 )
[root@nn01 protobuf-2.5.0]# ./configure
[root@nn01 protobuf-2.5.0]# make
[root@nn01 protobuf-2.5.0]# make install
(2) JDK 8 설치 (nn01, dn01, dn02)
① 현재 경로를 tmp 디렉토리로 변경한다.
[root@nn01 ~]# cd /tmp② vim을 다운 및 설치한다.
[root@nn01 ~]# yum install -y vim wget unzip
③ JDK 8 의 Linux 배포판을 다운 받는다.
[root@nn01 ~]# wget --no-check-certificate --no-cookies - --header "Cookie: oraclelicense=accept-securebackup-cookie" http://download.oracle.com/otn-pub/java/jdk/8u131-b11/d54c1d3a095b4ff2b6607d096fa80163/jdk-8u131-linux-x64.tar.gz
④ tmp 디렉토리 내에 jdk라는 이름으로 시작하는 모든 내역을 조회하면 jdk-8u131-linux-x64.tar.gz 만 출력된다.
[root@nn01 tmp]# ls jdk*
jdk-8u131-linux-x64.tar.gz
⑤ jdk-8u131-linux-x64.tar.gz 의 압축을 해제한다.
[root@nn01 tmp]# tar -xvzpf jdk-8u131-linux-x64.tar.gz
⑥ / opt / jdk / 1.8.0.131 경로를 만들고, 압축해제한 파일 전체를 옮긴다.
[root@nn01 tmp]# mkdir -p /opt/jdk/1.8.0_131
[root@nn01 tmp]# mv jdk1.8.0_131/* /opt/jdk/1.8.0_131/
⑦ / opt / jdk / 1.8.0_131 / 디렉토리에 대해 / opt / jdk / current 라는 이름으로 심볼릭링크를 생성한다.
이후부터 모든 연결은 current 라는 이름으로 진행함으로써,
나중에 jdk 의 버전이 바뀌더라도 동일한 심볼릭링크를 사용함으로써 설정에서의 편의성을 도모할 수 있다.
[root@nn01 tmp]# ln -s /opt/jdk/1.8.0_131 /opt/jdk/current
⑧ centos의 yum을 통해 java를 install하게 되면 버전관리 대상이 되어
OS에서 자동으로 JAVA의 버전을 업그레이드시킬 수 있다.
이를 방지하기 위해 alternatives 명령어를 사용하여 기존 버전을 유지할 수 있다.
[root@nn01 tmp]# alternatives --install /usr/bin/java java /opt/jdk/1.8.0_131/bin/java 2
[root@nn01 tmp]# alternatives --config java
There is 1 program that provides 'java'.
Selection Command
-------------------------------------------
*+ 1 /opt/jdk/1.8.0_131/bin/java
Enter to keep the current selection[+], or type selection number: 1을 입력해준다.
Enter to keep the current selection[+], or type selection number: 1
⑨ javac와 jar 명령어의 경로에도 alternatives 를 적용시켜준다. (권장)
[root@nn01 tmp]# alternatives --install /usr/bin/jar jar /opt/jdk/1.8.0_131/bin/jar 2
[root@nn01 tmp]# alternatives --install /usr/bin/javac javac /opt/jdk/1.8.0_131/bin/javac 2
[root@nn01 tmp]# alternatives --set jar /opt/jdk/1.8.0_131/bin/jar
[root@nn01 tmp]# alternatives --set javac /opt/jdk/1.8.0_131/bin/javac
⑩ JAVA의 버전을 확인해보면 최소 버전을 설치했기 때문에
openJDK 는 없고 직접 설치한 JAVA 1.8 버전만 있음을 확인할 수 있다.
[root@nn01 tmp]# java -version
java version "1.8.0_131"
Java(TM) SE Runtime Environment (build 1.8.0_131-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)
[root@nn01 tmp]# which java
/usr/bin/java
(3) 하둡 설치 ( nn01 / dn01 / dn02 )
① tmp 디렉토리로 이동한다.
[root@nn01 tmp]# pwd
/tmp
② hadoop-2.7.7 버전을 wget을 사용하여 다운받는다.
[root@nn01 tmp]# wget https://archive.apache.org/dist/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
③ tar 명령어를 사용하여 압축파일을 해제한다.
[root@nn01 tmp]# tar -xvzf hadoop-2.7.7.tar.gz
④ / opt / hadoop / 2.7.7 이라는 디렉토리 경로를 생성 후 압축해제한 파일들을 옮긴다.
[root@nn01 tmp]# mkdir -p /opt/hadoop/2.7.7
[root@nn01 tmp]# mv hadoop-2.7.7/* /opt/hadoop/2.7.7/
⑤ 해당 경로에 대하여 이후 연결을 담당하게 될 current 라는 이름의 심볼릭링크를 생성한다.
[root@nn01 tmp]# ln -s /opt/hadoop/2.7.7 /opt/hadoop/current
⑥ 2.7.7 디렉토리와 current 디렉토리의 목록을 출력해보면 동일하게 나오는 것을 확인할 수 있다.
[root@nn01 tmp]# ls /opt/hadoop/2.7.7/
bin etc include lib libexec LICENSE.txt NOTICE.txt README.txt sbin share
[root@nn01 tmp]# ls /opt/hadoop/current/
bin etc include lib libexec LICENSE.txt NOTICE.txt README.txt sbin share